2006-06-01
Abstract
John Graham-Cumming describes the aims and ideas behind the SpamOrHam project.
Copyright © 2006 Virus Bulletin
Many readers will recall the popular website HotOrNot (www.hotornot.com), where visitors could view pictures submitted by the public and vote (on a scale of 1 to 10) whether the person depicted was 'hot' or not. SpamOrHam (www.spamorham.org) uses the same principle to sort a large collection of emails into those that are spam and those that are genuine messages, or ham.
SpamOrHam's first task is to check the sorting of the 2005 TREC Public Spam Corpus. In the January 2006 issue of Virus Bulletin, Gordon Cormack described the results of the spam track of the 2005 Text Retrieval Conference (TREC) – for which the 2005 TREC Public Spam Corpus was created (see VB, January 2006, p.S2).
The spam track tested a range of spam-filtering technologies against four corpuses of spam and ham. Three of the corpuses were from private individuals and were not released, the fourth, now known as the 2005 TREC Public Spam Corpus, consists of ham messages released during the course of the Enron investigation and spam messages drawn from a public archive. All 92,189 messages in the public corpus are available for download at http://plg.uwaterloo.ca/~gvcormac/treccorpus/.
Using a variety of techniques – starting with various existing spam filters, and calling upon humans where the spam filters disagreed – the messages were sorted into spams and hams. The public corpus download includes a file that describes this 'gold standard'. Details of the creation of the public corpus can be found in Cormack and Lyman's 2005 CEAS paper 'Spam corpus creation for TREC' (http://www.ceas.cc/papers-2005/162.pdf).
A visitor to SpamOrHam is presented with emails drawn randomly from the 2005 TREC Public Spam Corpus in two forms: an image of the email rendered using Microsoft Outlook 2002 and the complete raw message including full headers and body. The user is invited to click on one of three buttons: 'This is Spam', 'This is Ham' or 'I'm not sure'. Each vote by a user is recorded for later comparison with the gold standard.
To ensure that the site is responsive, all 92,189 emails were rendered by importing them into Microsoft Outlook 2002 and then each message was opened and a screen shot taken which was saved as a GIF with a filename that matches the name of the message in the 2005 TREC Public Spam Corpus. When a user visits the site the server side code reads the raw message from a copy of the corpus on the site and displays the GIF generated.
The generation of the GIF files was one of the most time-consuming tasks in the creation of the SpamOrHam site. Ignoring the time taken to write the necessary code and deal with various errors along the way, importing all 92,189 messages into Microsoft Outlook took 34 hours on a 2.4 GHz PC running Windows 2000 with 1 Gb of RAM. Rendering the screen shots of each email took 46 hours with the CPU running at 100% utilization throughout. The rendering generated just under 3 Gb of GIF files.
To prevent abuse of the site the user is challenged periodically with a CAPTCHA. The CAPTCHA asks the user to enter a sequence of letters displayed in an image on a fuzzy background (there is also a link to an MP3 file so that disabled users can take part). If the password is not entered correctly the user's vote is not recorded and they are presented with another CAPTCHA to solve. Once they pass the CAPTCHA test the user will be presented with up to ten emails to vote on before being asked to prove that they are a human with another CAPTCHA image.
One interesting feature of the site is that it stores no state on the server side. The entire state for each user is stored in hidden form fields that are protected using a secure hash. Any attempt to tamper with the form fields, or submit forged information, is detected by the value of the hash. Such fraudulent votes are discarded and a record is kept of the abusive IP address. Further details of this mechanism can be found in this blog entry: http://www.jgc.org/blog/2006/04/stateless-web-pages-with-hashes.html.
Examining the error logs of SpamOrHam has shown that although some potential attempts to subvert the purpose of the site have been detected, the biggest problem is that humans have a hard time with the CAPTCHA. Around 20% of the CAPTCHA images presented to users are interpreted incorrectly, leading to a second CAPTCHA being presented. The biggest problem seems to be distinguishing the letters i and l against the fuzzy background.
SpamOrHam launched on 29 April 2006 and at the time of writing, over 207,000 votes have been cast against the 92,189 messages in the dataset. Around 11,000 messages have not yet been voted on (the expected value for a truly random selection across the messages would be around 9,700; however, due to a bug in the random selection code some messages were not initially being selected – the bug has now been fixed). SpamOrHam aims to collect one million votes with the goal that each message be voted on multiple times.
Although the site is only one fifth of the way towards its goal some initial conclusions can be drawn. Of the 81,013 emails voted on by the general public, 53,802 have been voted on more than once and the votes agree with the TREC gold standard. A further 20,707 have been voted on just once while still agreeing. That means that the public and the machine classification of the messages agree on 91.7% of the messages.
The remaining 6,504 messages are divided into three groups: there are 1,894 messages that have been voted on once and the voters disagreed with the gold standard; there are 2,992 messages that have been voted on multiple times but the votes cancel out (for example, one person says spam and another says ham); and there are 1,618 messages where multiple voters have seen an email and the overall votes show disagreement with the TREC gold standard.
Focusing on just these 1,618 messages shows some surprising results (at the time of writing, not all 1,618 have been examined). The overall impression is that, although SpamOrHam has found some errors in the gold standard, the ability of people to spot the difference between genuine messages and spam or phishes is open to question.
Bill Yerazunis, creator of the CRM114 spam filter, has measured his own accuracy at determining whether a message is spam or not and indicates that he achieves 99.84% accuracy (see http://www.paulgraham.com/wsy.html). In my 2005 MIT Spam Conference presentation 'People and Spam' I reported on a previous test of the general public's ability to sort email messages (see http://www.jgc.org/pdf/spamconf2005.pdf), which yielded an accuracy of 99.46%. The error rate for the SpamOrHam test looks like it will be much higher, with humans being able to identify only around 98% of messages correctly.
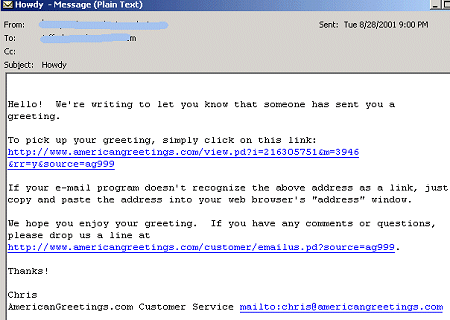
People's perception of what constitutes spam should worry legitimate email marketers. Figure 2 is an example of a legitimate e-card that members of the public consider to be spam; there are multiple instances of SpamOrHam voters considering e-cards to be spam.
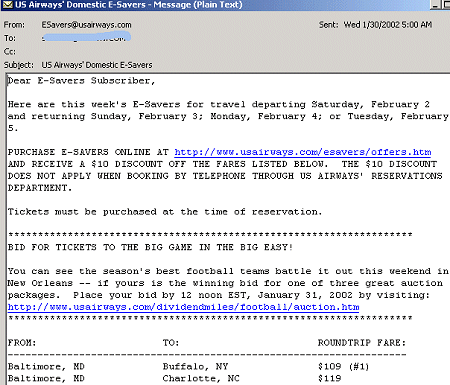
The same was true of the legitimate email from US Airways shown in Figure 3; multiple SpamOrHam voters see it as spam.
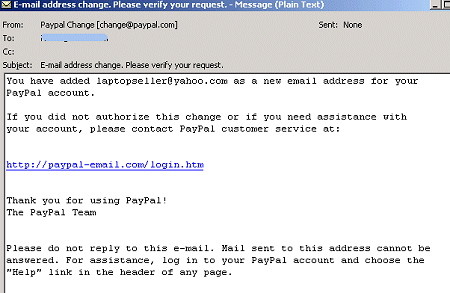
And the dangers of phishing are illustrated clearly by the fraudulent PayPal message shown in Figure 4, which many voters think is legitimate.
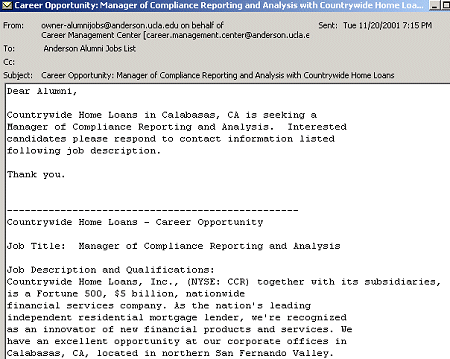
Happily, since this was the original goal, users of SpamOrHam have found some errors in the 2005 TREC Public Spam Corpus. The email shown in Figure 5, which was sent to an alumni mailing list, is listed incorrectly as spam in the public corpus, but multiple voters agree that it is legitimate.
The inaccuracy of humans when sorting email messages has an important effect on the testing of spam filters and the design of anti-spam technologies.
The first difficulty highlighted by SpamOrHam is in the creation of test corpuses. If spam filters are to be tested reliably, it is essential that test data (both spam and ham messages) is available and that the test data is split accurately into spams and hams.
Since all tests performed so far on humans filtering messages show that they cannot be trusted to provide 100% accurate results, the results of spam-filtering tests need to be viewed with caution. If a spam filter test says that filter A is 99.2% accurate and filter B is 98.5% accurate, it's not possible to tell which filter is better without knowing the margin for error in the original test dataset.
Taking into account human fallibility probably means that humans have an error rate of up to 2% over large sets of messages. Results of spam filter tests need to account for that initial error rate.
Secondly, many anti-spam products contain a quarantine where suspected spam messages are placed, and users are invited to review the captured messages in an attempt to spot false positives (legitimate messages that have been quarantined mistakenly). Equally, some spam-filtering products invite users to teach the system which messages are spam by forwarding spam messages that they have received mistakenly.
However, if the error rate for humans is high, this feedback loop with the anti-spam product may cause the spam filter to perform more poorly than a filter that receives no feedback. For example, if users report that a legitimate email (such as the US Airways marketing mail) is spam, a spam filter may begin quarantining all US Airways marketing mail for all users sharing the same anti-spam system. This may mean that per-user configuration is necessary to prevent users from interfering with each other's preferences.
On the other hand, users who fall for phishing emails may be allowing more phishing messages to be delivered if their erroneous retrieval of phishing mails from quarantine causes a spam filter to start letting them through.
Finally, there is much disagreement about the definition of spam (a commonly heard adage in anti-spam circles is: 'one man's spam is another man's ham'). This may be reflected in the treatment of marketing messages in the SpamOrHam tests, and anecdotal evidence indicates that users will feed back emails sent from legitimate mailing lists, marking them as spam, as a way to unsubscribe without going through the email marketer's actual unsubscribe option.
This behaviour has been made worse by the practice of some spammers to include unsubscribe links in spam; users who try to unsubscribe in fact receive more spams, having 'confirmed' their email address for the spammer.
The SpamOrHam test is still in progress. Once one million votes have been registered the complete data from SpamOrHam will be made public in the form of raw vote data so that anyone can use it for their own research in conjunction with the 2005 TREC Public Spam Corpus.
In addition to gathering the raw votes, SpamOrHam is also recording information about the amount of time people spend examining mail before making a decision about whether a message is spam or not.
This timing data will also be made public. Finally, SpamOrHam is actively looking for suggestions on how to analyse the data gathered. Please feel free to drop me a line at <[email protected]> with your thoughts.