2006-01-01
Abstract
The 14th Text Retrieval Conference (TREC 2005) took place in November 2005. One of the highlights of the event was the TREC spam filter evaluation effort. Gordon Cormack has all the details.
Copyright © 2006 Virus Bulletin
The 14th Text Retrieval Conference (TREC 2005) took place in November 2005. One of the highlights of the event was the TREC spam filter evaluation effort, in which 53 spam filters developed by 17 organizations were tested on four separate email corpora totalling 318,482 messages. The purpose of the exercise was not to identify the best entry; rather to provide a laboratory setting for controlled experiments. The results provide a helpful insight into how well spam filters work, and which techniques are worthy of further investigation.
The technique of using data compression models to classify messages was demonstrated to be particularly worthy, as evidenced by the fine performance of filters submitted by Andrej Bratko and Bogdan Filipi of the Josef Stefan Institute in Slovenia. Other techniques of note are the toolkit approach of Bill Yerazunis' CRM114 group and the combination of weak and strong filters by Richard Segal of IBM.
Each spam filter was run in a controlled environment simulating personal spam filter use. A sequence of messages was presented to the filter, one message at a time, using a standard command-line interface. The filter was required to return two results for each message: a binary classification (spam or ham [not spam]), and a 'spamminess' score (a real number representing the estimated likelihood that the message is spam). After returning this pair of results, the filter was presented with the correct classification, thus simulating ideal user feedback. The software created for this purpose – the TREC Spam Filter Evaluation Tool Kit – is available for download under the Gnu General Public License (http://plg.uwaterloo.ca/~trlynam/spamjig/).
The spam track departed from TREC tradition by testing with both public and private corpora. The public corpus tests were carried out by participants, while the private corpus tests were carried out by the corpus proprietors. This hybrid approach required participants both to run their filters, and to submit their implementations for evaluation by third parties.
The departure from tradition was occasioned by privacy issues which make it difficult to create a realistic email corpus. It is a simple matter to capture all the email delivered to a recipient or set of recipients. However, acquiring their permission, and that of their correspondents, to publish the email is nearly impossible. This leaves us with a choice between using an artificial public collection and using a more realistic private collection. The use of both strategies allowed us to investigate this trade off.
The three private corpora each consisted of all the email (both ham and spam) received by an individual over a specific period. The public corpus came from two sources: Enron email released during the course of the Federal Energy Regulatory Commission’s investigation, and recent spam from a public archive. The spam was altered carefully so as to appear to have been addressed to the same recipients and delivered to the same mail servers during the same period as the Enron email. Despite some trepidation that evidence of this forgery would be detected by one or more of the filters, the results indicate that this did not happen.
To form a test corpus, each message must be augmented with a gold standard representing the true classification of a message as ham or spam. The gold standard is used in simulating user feedback and in evaluating the filter's effectiveness. As reported previously (see VB, May 2005, p.S1), much effort was put into ensuring that the gold standard was sufficiently accurate and unbiased. Lack of user complaint is insufficient evidence that a message has been classified correctly. Similarly, we believe that deleting hard-to-classify messages from the corpus introduces unacceptable bias. In comparing the TREC results with others, one must consider that these and other evaluation errors may tend to overestimate filter performance.
The primary measures of classification performance are ham misclassification percentage (hm%) and spam misclassification percentage (sm%). A filter makes a trade-off between its performances on these two measures. It is an easy matter to reduce hm% at the expense of sm%, and vice versa. The relative importance of these two measures is the subject of some controversy, with the majority opinion being that reducing hm% is more important, but not at all costs with respect to increasing sm%. At TREC we attempted to sidestep the issue by reporting the logistic average (lam%) of the two scores, which rewards equally the same multiplicative factor in ham or spam misclassification odds. More formally:
lam% = logit-1 = ( logit(hm%) + logit(sm%) ) / 2
where
logit(x) = log(odds(x))
and
odds(x) = x / (100% - x)
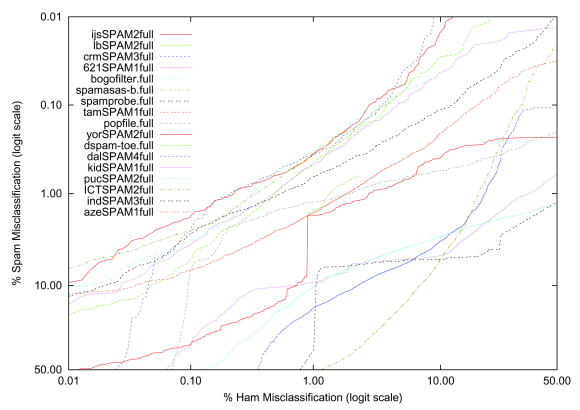
Another way to sidestep the trade-off issue is to use the spamminess score to plot a Receiver Operating Characteristic (ROC) curve that represents all (hm%, sm%) pairs that could be achieved by the filter by changing a threshold parameter. Figure 1 shows the ROC curve for the best filter from each organization, as tested on the public corpus. In general, higher curves indicate superior performance regardless of the trade off between hm% and sm%, while curves that intersect indicate different relative performance depending on the relative importance of hm% and sm%. The solid curve at the top (ijsSPAM2full; Bratko's filter) shows sm% = 9.89% when hm% = 0.01%, sm% = 1.78% when hm% = 0.1%, and so on.
A useful summary measure of performance is the area under the ROC curve, ROCA, a number between 0 and 1 that indicates overall performance. In addition to the geometric interpretation implied by its name, this area represents a probability: the probability that the filter will give a random spam message a higher spamminess score than a random ham message. TREC reports (1-ROCA) as a percentage, consistent with the other summary measures which measure error rates rather than success rates.
TREC 2005's spam evaluation used three summary measures of performance: lam%, (1-ROCA)%, and sm% at hm% = 0.1. Each provides a reasonable estimate of overall filter performance; none definitively identifies the best filter.
The TREC spam evaluations generated a vast number of curves and statistics, which will appear in the TREC 2005 proceedings to be published early in 2006 (http://trec.nist.gov/pubs.html). We summarize the results with respect to the public corpus.
Table 1 associates each of the selected test runs (i.e. the best per organization) with its author. Only 12 of the filters were authored by official TREC 2005 participants; the other five were popular open-source spam filters, configured by the spam track organizers in consultation with their authors.
| Run | Comment | Author |
|---|---|---|
| bogofilter | Bogofilter (open source) | David Relson (non-participant) |
| ijsSPAM2 | PPM-D compression model | Andrej Bratko (Josef Stefan Institute) |
| spamprobe | SpamProbe (open source) | Brian Burton (non-participant) |
| spamasas-b | Spamassassin Bayes filter only (open source) | Justin Mason (non-participant) |
| crmSPAM3 | CRM-114 (open source) | Bill Yerazunis (MERL) |
| 621SPAM1 | Spam Guru | Richard Segal (IBM) |
| lbSPAM2 | dbacl (open source) | Laird Breyer |
| popfile | Popfile (open source) | John Graham-Cumming (non-participant) |
| dspam-toe | DSPAM (open source) | Jon Zdziarski (non-participant) |
| tamSPAM1 | SpamBayes (open source) | Tony Meyer |
| yorSPAM2 | Jimmy Huang (York University) | |
| indSPAM3 | Indiana University | |
| kidSPAM1 | Beijing U. of Posts & Telecom. | |
| dalSPAM4 | Dalhousie University | |
| pucSPAM2 | Egidio Terra (PUC Brazil) | |
| ICTSPAM2 | Chinese Academy of Sciences | |
| azeSPAM1 | U. Paris-Sud |
Table 1. The selected test runs and their authors.
Table 2 shows the three classification-based measures (hm%, sm%, and lam%) for each filter, ordered by lam%. Note that hm% and sm% give nearly opposite rankings, indicating their heavy negative correlation and dependence on threshold setting.
| Run | Hm% | Sm% | Lam% |
|---|---|---|---|
| bogofilter | 0.01 | 10.47 | 0.30 |
| ijsSPAM2 | 0.23 | 0.95 | 0.47 |
| spamprobe | 0.15 | 2.11 | 0.57 |
| spamasas-b | 0.25 | 1.29 | 0.57 |
| crmSPAM3 | 2.56 | 0.15 | 0.63 |
| 621SPAM1 | 2.38 | 0.20 | 0.69 |
| lbSPAM2 | 0.51 | 0.93 | 0.69 |
| popfile | 0.92 | 1.26 | 0.94 |
| dspam-toe | 1.04 | 0.99 | 1.01 |
| tamSPAM1 | 0.26 | 4.10 | 1.05 |
| yorSPAM2 | 0.92 | 1.74 | 1.27 |
| indSPAM3 | 1.09 | 7.66 | 2.93 |
| kidSPAM1 | 0.91 | 9.40 | 2.99 |
| dalSPAM4 | 2.69 | 4.50 | 3.49 |
| pucSPAM2 | 3.35 | 5.00 | 4.10 |
| ICTSPAM2 | 8.33 | 8.03 | 8.18 |
| azeSPAM1 | 64.84 | 4.57 | 22.92 |
Table 2. The classification-based measures, ordered by lam%.
Table 3 shows the three summary measures: (1-ROCA)%, hm% at sm% = 0.1%, and lam% and the rank of each filter according to each of the measures. Note that while the rankings are not identical, they have a high positive correlation. The measures with respect to the other corpora vary somewhat but give the same general impression.
| Run | (1-ROCA)% | Rank | Sm% @ Hm%=0.1 | Rank | Lam% | Rank |
|---|---|---|---|---|---|---|
| ijsSPAM2 | 0.02 | 1 | 1.8 | 1 | 0.5 | 2 |
| lbSPAM2 | 0.04 | 2 | 5.2 | 7 | 0.7 | 7 |
| crmSPAM3 | 0.04 | 3 | 2.6 | 3 | 0.6 | 5 |
| 621SPAM1 | 0.04 | 4 | 3.6 | 6 | 0.7 | 6 |
| bogofilter | 0.05 | 5 | 3.4 | 5 | 0.3 | 1 |
| spamasas-b | 0.06 | 6 | 2.6 | 2 | 0.6 | 3 |
| spamprobe | 0.06 | 7 | 2.8 | 4 | 0.6 | 4 |
| tamSPAM1 | 0.16 | 8 | 6.9 | 8 | 1.1 | 10 |
| popfile | 0.33 | 9 | 7.4 | 9 | 0.9 | 8 |
| yorSPAM2 | 0.46 | 10 | 34.2 | 10 | 1.3 | 11 |
| dspam-toe | 0.77 | 11 | 88.8 | 15 | 1.0 | 9 |
| dalSPAM4 | 1.37 | 12 | 76.6 | 13 | 3.5 | 14 |
| kidSPAM1 | 1.46 | 13 | 34.9 | 11 | 3.0 | 13 |
| pucSPAM2 | 1.97 | 14 | 51.3 | 12 | 4.1 | 15 |
| ICTSPAM2 | 2.64 | 15 | 79.5 | 14 | 8.2 | 16 |
| indSPAM3 | 2.82 | 16 | 97.4 | 16 | 2.9 | 12 |
| azeSPAM1 | 28.89 | 17 | 99.5 | 17 | 22.9 | 17 |
Table 3. The summary measures and the rank of each filter according to those measures.
The most startling observation is that character-based compression models perform outstandingly well for spam filtering. Commonly used open-source filters perform well, but not nearly so well or nearly so poorly as reported elsewhere. We have reason to believe that reports on the performance of other filters are similarly unreliable; only standard evaluation will test their credence.
The main result from TREC is the toolkit and methods for filter evaluation. These may be used by anyone to perform further tests. The public corpus will be made available to all, subject to a usage agreement. The private corpora will remain in escrow so that new filters may be tested with them. Plans are already under way for TREC 2006, in which the same and new tests will be conducted on new filters and corpora. The new tests will include modelling of unreliable user feedback, use of external resources and other email processing applications.