2016-01-01
Abstract
In their VB2014 paper, Jonathan Oliver and his colleagues look at abuse on Twitter.
Copyright © 2014 Virus Bulletin
In this paper, we examine Twitter in depth, including a study of 500,000,000 Tweets collected over a two-week period in order to analyse how the micro-blogging site is abused.
Most Twitter abuse takes the form of Tweets containing links to malicious websites. These websites take many forms, including spam sites, scam sites that are involved in compromising more Twitter accounts, phishing sites, and sites hosting malware or offering cracked versions of software. Many of the malicious Tweets are sent from legitimate accounts that have been compromised, causing a range of problems for their owners.
The scale of the threat is significant. Previous research, notably [1], has indicated that the use of URL blacklists is ineffective in detecting Twitter threats. However, our research shows otherwise – approximately 5% of all Tweets with links had malicious and/or spammy content.
We also applied graph algorithms to the Twitter data and were able to find various clusters of interrelated websites and accounts. We were able to identify specific Tweet spam campaigns as well as the groups carrying out these campaigns.
The data from this analysis leads us to conclude that blacklisting, in conjunction with other analytical tools, is an effective tool for identifying malicious Tweets.
Researchers from Trend Micro and Deakin University worked together to investigate the Twitter threat landscape. This paper features a comprehensive study that lasted for two weeks from 25 September to 9 October 2013, including further analysis of some of the threats we discovered over the given period. The study revealed a significant level of abuse of Twitter, including spamming, phishing, and sharing of links that led to malicious and potentially illegal websites. The majority of the malicious messages we observed were sent from compromised accounts, many of which have subsequently been suspended by Twitter.
A 2010 study [1] examined 400 million public Tweets and 25 million URLs. The authors identified two million URLs (8%) that pointed to spamming, malware-download, scamming and phishing websites, leading them to conclude (a) that blacklists were ineffective, as these only protected a minority of users, and (b) that the use of URL shorteners made the task of identifying malicious links very difficult.
This research paper begins by giving a brief overview of the types of Twitter abuse we discovered within our study period. It then provides a summary of the data we collected to learn more about the abuse. Given the data, we examined a range of issues, including: (a) the use of blacklists to detect Twitter spam, (b) the coordinated nature of certain Twitter spam outbreaks, (c) the timing of spam outbreaks, and (d) details related to particular Twitter scams. In Section 4, we propose an approach for analysing Twitter spam outbreaks which is very useful in augmenting blacklists for the detection of Twitter spam.
This Section provides a brief overview of the Twitter threats we found. It also provides examples of the most active threat types, including: traditional spam similar to email spam, searchable spam (which differed from email spam), phishing messages, and suspended and compromised accounts.
The following are some of the features of traditional Twitter spam:
The Tweets typically promoted weight-loss drugs, designer sunglasses and bags, etc., very much like email spam.
Unrelated, but often-trending hash tags were used to increase Tweet distribution and to encourage more people to click the links.
The Tweets included misspelled words, sometimes substituting numbers for letters, which was typical of email spam 10 years ago.
In some cases, URL shorteners were used to make it more difficult for security analysts to identify which Tweets point to spam websites.
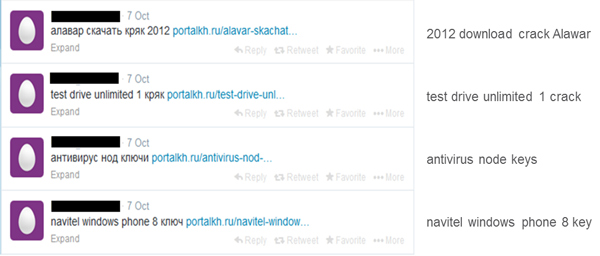
Figure 1 shows examples of searchable Twitter spam.
The following are some of the features of searchable spam:
The messages typically promote free access to copyrighted and licensed materials or offer gadget knock offs. For example: solutions to homework and exam cheat sheets, free movie downloads, cracked versions of software, and computer, printer and mobile device knock offs.
Hash tags are not used, or are only used sparingly.
Many such Tweets are written in Russian.
Several domains are used, many of which are hosted in Russia and in the Ukraine.
Our analysis of searchable spam revealed that the probability of Twitter suspending an account involved with a searchable spam incident was significantly lower than if it was involved in sending out traditional Twitter spam or other malicious messages. In addition, we found that 50% of those who clicked the links in searchable spam written in Russian were from non Russian-speaking countries such as the United States and Japan (see Section 7). This type of spam typically remains on Twitter after transmission and can easily be searched for. For example, Group A, described in Section 5, consists of over 7.8 million searchable spam messages. Approximately 90% of these remain accessible on Twitter at the time of writing this paper.
We conclude that searchable spam attempts to avoid irritating users so that it will not be reported via the ‘Abuse’ button that Twitter has made available. Searchable spam covers a wide range of content, which some users might be motivated to look for using Twitter’s Search function. They might even be willing to use automated translation tools to understand the content of such spam.
We examined a long-running phishing scam [2] that exploits certain Twitter features. The scam starts with a compromised user sending messages to friends (using the @ syntax on Twitter). The messages ask them to click a shortened URL –clicking the link starts a redirection chain that ends at a phishing page that tells the user their session has timed out and that they need to log in again. In the course of our research, we attempted to estimate the scale of this problem, which we discuss in Section 8.
While carrying out our research, we followed some of the accounts that had been involved in spamming. We attempted to access them in December 2013 (two months after the period of data collection). We found that Twitter had suspended tens of thousands of accounts involved in spamming and in other malicious activities. Many of these accounts appeared to have been created specially for this purpose – the accounts were created, and then immediately started sending spam. In some cases, genuine account owners had identified the problem and taken corrective actions to restore their accounts. However, this was significantly rarer than account suspension. (We do not have statistics on this because it was difficult to establish when compromises occurred; we only have anecdotal evidence of their occurrence.)
We collected as many Tweets with embedded URLs as possible within the two-week period from 25 September to 9 October 2013. We restricted the Tweets we examined to those with embedded URLs. While it is possible to use Twitter to send spam and other messages without URLs, the majority of the spam and other malicious messages we found on Twitter contained embedded URLs. Among the thousands of spam messages that humans inspected in the course of our research, we only found a handful of Tweets without URLs that could be considered abusive or harmful.
We categorize Tweets that contain malicious URLs as ‘malicious Tweets’. The data we collected is shown in Table 1. We gathered a total of 573.5 million Tweets containing URLs and identified 33.3 million malicious Tweets, which accounted for approximately 5.8% of all of the Tweets with URLs . We used two methods to identify malicious Tweets. The first involved the use of the Trend Micro Web Reputation Technology [3], which uses a blacklist. The second method involved identifying groups of malicious Tweets using the clustering algorithm described in Section 4. Note that we experienced a disruption in our data collection process on 29 and 30 September 2013, which accounted for data loss during said period.
| Day/date | Number of Tweets with URLs | Number of malicious Tweets | Percentage of malicious Tweets |
|---|---|---|---|
| Wednesday 09/25/2013 | 39,257,353 | 2,292,488 | 5.8% |
| Thursday 09/26/2013 | 47,252,411 | 3,190,600 | 6.8% |
| Friday 09/27/2013 | 49,465,975 | 3,947,515 | 8.0% |
| Saturday 09/28/2013 | 37,806,326 | 2,018,935 | 5.3% |
| Sunday 09/29/2013 | - | - | - |
| Monday 09/30/2013 | - | - | - |
| Tuesday 10/1/2013 | 48,778,630 | 2,511,489 | 5.1% |
| Wednesday 10/2/2013 | 51,728,355 | 3,739,597 | 7.2% |
| Thursday 10/3/2013 | 51,638,205 | 3,932,186 | 7.6% |
| Friday 10/4/2013 | 49,230,861 | 3,398,526 | 6.9% |
| Saturday 10/5/2013 | 44,165,664 | 2,293,539 | 5.2% |
| Sunday 10/6/2013 | 45,089,730 | 2,006,447 | 4.4% |
| Monday 10/7/2013 | 50,457,403 | 2,305,794 | 4.6% |
| Tuesday 10/8/2013 | 42,031,232 | 1,152,119 | 2.7% |
| Wednesday 10/9/2013 | 16,612,318 | 538,133 | 3.2% |
| TOTAL | 573,514,463 | 33,327,368 | 5.8% |
Table 1. Data collected.
One of our research goals was to obtain a high-level understanding of the various types of spam and scams on Twitter. We determined that one approach to achieving this aim would be to cluster malicious Tweets into groups. Forming clusters of malicious Tweets would be successful if we could explain adequately why Tweets in a group are considered similar to one another, and why they are considered malicious.
Several possible variables could be extracted from Tweets, including: content, embedded URLs, hash tags and sender data, including frequency. It would prove very useful if it were possible to group Twitter spam into distinct outbreaks rather than try to understand a huge mass of data. Traditional approaches for doing this include grouping spam Tweets that have similar content or applying machine-learning approaches. Applying machine-learning approaches involves extracting numerical or categorical variables from Tweets and users (e.g. how often they send messages, dramatic changes in their behaviour, etc.) and applying a statistical or machine-learning approach to the data (e.g. SVMs or Nearest Neighbor).
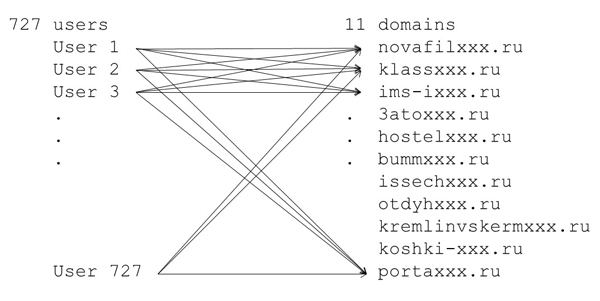
We took another approach. Our proposal for identifying certain classes of high-volume spam was to create a graph consisting of senders and domains in URLs and to identify bipartite cliques [4] in this graph. Such graphical approaches to identifying cliques in data have previously been applied to computer security problems [5]. To do this, we constructed a graph where the Twitter users are nodes on the left-hand side of the graph while the domains in links are nodes on the right-hand side. For each Tweet from User U that contains a link with Domain D, we include an arc in the graph from User U to Domain D. Some spammers use applications that employ a round-robin approach for sending spam. Given a number of sending accounts and destinations for URLs in the Tweets, the use of a round-robin approach maximizes the number of spam messages while minimizing the effects of (i) having their accounts suspended and (ii) blacklists blocking their spam. When the graphical approach described above is used, a set of users involved in a round-robin approach will generate a bipartite clique in the graph. Hence, bipartite cliques in such a graph are very suspicious – the probability of real users behaving this way in the normal course of events is extraordinarily small. There are scalable approaches for using map-reduce [6, 7] to identify cliques in large data sets.
Figure 2 provides an example of a bipartite clique found in the data, which consists of 727 users who sent Tweets containing links to 11 domains; all of the users in the clique sent Tweets containing links to all of the domains in the clique.
This approach is well suited to understanding certain types of Twitter spamming behaviours, but unsuited to others. For example, it is not suitable for analysing the Twitter follower scam described in Section 6, since that did not use a round-robin approach for sending messages. The Twitter follower scam was confirmed as malicious by installing the app and monitoring its behaviour.
Other malicious behaviour was identified by following the links through to the final website and confirming that the website was malicious.
We applied the clique algorithm described in Section 4 [6] to the Twitter data we collected. The algorithm identified 16 cliques, each of which accounted for 1% or more of the Twitter spam. Table 2 describes each of the cliques generated. In addition, Group G was a Twitter follower spam group, which accounted for 2.5% of the Twitter spam.
| Description | Percentage of malicious Tweets | Number of senders | Hash tags | Number of domains | Percentage of suspended accounts |
|---|---|---|---|---|---|
| A. Education spam, etc. | 27.28% | 797 | None | 24 | 10.3% |
| B. Cracked software and game spam | 8.11% | 578 | None | 20 | 31.5% |
| C. Education spam | 6.26% | 539 | None | 20 | 19.7% |
| D. Cracked software spam | 6.19% | 9,509 | Limited[a] | 21 | 12.0% |
| E. Cracked software spam | 4.39% | 727 | None | 11 | 11.6% |
| F. Printer/mobile spam | 3.72% | 12,275 | Low | 3 | 89.1% |
| G. Twitter follower spam | 2.54% | 59,205 | Yes | 1 | 2.1% |
| H. Video/mobile/cracked software/game spam | 2.23% | 8,987 | Low | 50 | 95.2% |
| I. Game and computer spam | 2.04% | 608 | None | 19 | 97.9% |
| J. Education spam, etc. | 1.99% | 284 | None | 14 | 47.9% |
| K. Shirt spam | 1.91% | 1,699 | None | 5 | 74.7% |
| L. Game, mobile, and printer spam | 1.81% | 1,197 | None | 18 | 98.8% |
| M. Computer/printer spam | 1.77% | 26,603 | Low | 60 | 42.3% |
[a] 12.5% of the users from this group included the hash tag ‘#fgsdfg,’ which has been used in subsequent spam outbreaks. The most recent outbreak (at the time of writing this paper) was seen on 8 January 2014. | |||||
Table 2. High-level perspective.
![]()