2011-06-01
Abstract
'Under IPv6, spammers could send out one piece of spam per IPv6 address, discard it and then move on to the next address for the next 10,000 years and never need to re-use a previous address.' Terry Zink explains why mail providers are not thrilled about using IPv6 to handle email.
Copyright © 2011 Virus Bulletin
Over recent months, anti-spam bloggers have written about IPv6 and the challenges it poses for the email industry. John Levine, an author of numerous RFCs and a couple of books about spam fighting, wrote the following [1]:
‘We will eventually figure out both how people use IPv6 addresses for mail, and how to manage and publish v6 reputation data, but until then, running a mail server on v6 will be a lot harder than running one on v4. And since you’ll be able to handle all the real mail on v4, why bother [running a mail server to handle IPv6]?’
Barry Leiba, another email security writer, writes the following on Circle ID [2]:
‘John Levine has one approach: leave the email system on IPv4 for the foreseeable future. Even, John points out, when many other services, customer endpoints, mobile and household devices, and the like have been – have to have been – switched to IPv6, we can still run the Internet email infrastructure on IPv4 for a long time, leaving the IP blocklists with v4 addresses, and a system that we’re already managing fine with.
‘Of course, some day, we’ll want to completely get rid of IPv4 on the Internet, and by then we’ll need to have figured out a replacement for the IP blocklist mechanism. But John’s right that that won’t be happening for many years yet, and he makes a good case for saying that we don’t have to worry about it.’
Both writers are saying the same thing, and I have been on discussion threads where the consensus was similar: there is no agreement on how to handle IPv6 over email in the short term, but eventually it will have to be figured out. There are some who believe that mail will never move to IPv6 and some who think that it will go there one of these days. In the meantime, we just use IPv4 to send mail.
To expand a bit on what both writers are saying, the biggest reason why mail providers are not thrilled about using IPv6 to handle email is because there is currently no way to deal with the problem of abuse. Today, spammers make extensive use of botnets. Each day, they compromise new machines and start using them to spew out spam. Each of these bots uses a different IP address, and the IP addresses change all of the time. If you had 10,000 IP addresses that were sending out spam today, then tomorrow there would also be 10,000, but at least 9,700 of them would be different IP addresses from those used today.
The reason there is so much rotation in IP addresses is because modern spam filters make use of IP blocklists. When a blocklist service detects that an IP is sending spam, it adds it to the blocklist and rejects all mail from it. There are exceptions to this listing process such as a legitimate IP that sends a majority of good mail (such as a Hotmail or Gmail IP address), but in general, mail servers reject all mail from blocklisted IPs. The reasons they do this are:
90% of all email flowing across the Internet (not including internal mail within an organization) is spam. If a sending IP is on a blocklist, a mail server can reject it in the SMTP transaction and save on all of the processing costs associated with accepting the message and filtering it in the content filter. Most mail servers today would topple over and crash if they had to handle all of the mail coming from blocklisted IPs because it would increase the number of total messages by a factor of 10.
Spam filters get slightly better anti-spam metrics by using IP blocklists. Content filters are good, but rejecting 100% of mail from a spamming IP address means that there is no possibility of a false negative from that IP address. By contrast, if a spam filter does not use an IP blocklist, the content filter has to learn to recognize the spam coming from that IP address, update the filter and then replicate out the changes. This is slower than pulling down a blocklist and then using it as the first line of defence. Without an IP blocklist, a spam filter will filter between 80% and 99% of the mail coming from a blocklisted IP. While many spam filters get close to that 99% range, it’s still not 100%.
Blocklists are populated in a number of different ways. Some use spam traps to capture mail sent to email addresses that have never been used publicly, while others use statistical algorithms to judge that a sender is malicious (or compromised). Once the data is acquired, blocklist operators publish their lists in two ways:
They list individual IP addresses of all the servers that are sending mail.
They make use of CIDR (Classless Internet Domain Routing) notation. CIDR is a way to group large blocks of IP addresses. A provider would list a larger group of IP addresses in CIDR notation in order to save on space in the file so they don’t have to list them one by one. For example, the Spamhaus Exploits Block List (XBL) is about 7 million entries (lines of text) and around 100MB in size. By contrast, the Spamhaus PBL (which lists IP ranges which should not be delivering unauthenticated SMTP mail to any Internet server) contains 200,000 lines of text (without exceptions in ! notation) and is 6MB. However, the PBL is represented mostly in CIDR notation. If all of these ranges were expanded, it would be over 650 million individual IP addresses. That’s a whole heck of a lot more IPs in the PBL for a whole lot less file size.
Today in Forefront Online, we run the XBL in front of the PBL and it blocks about four times as much mail as PBL (I don’t know how much would be blocked if we ran them in reverse). The XBL is better at catching individual bots that are sending out spam but are not listed anywhere (they are new IPs), whereas the PBL is better at pre-emptively catching mail servers that should never send out spam (probable bots but it doesn’t matter because they shouldn’t be sending mail anyhow). However, if we had to list every single PBL IP singly instead of compressing it into CIDR ranges, and using the same ratio of 7 million IPs to ~100MB, then the PBL would be 9.4GB in total size. 9.4GB is a large file. It isn’t completely unmanageable but it changes from being a minor inconvenience to being a major one. It takes a long time to download, upload and process a 9.4GB file. It’s also easier to store the file entries in a database if there are only 500,000 entries (or even 7 million) vs 650 million of them. Databases that are as large as that run into the problem of scale.
The PBL and XBL are examples of why different styles of IP blocklists are required. The PBL lists 650 million IPs and we still have over 7 million IPs on the XBL that aren’t on the PBL. Clearly, spamming bots can move around such that they are not published on the lists that have large address spaces listed. Bots are very good at hiding in places that are not blocked yet. Given enough space, spammers will hide because if they didn’t they would not be able to stay in business. The problem that the industry faces is that as soon as we find a spammer’s hiding space, we can block it for a while but the spammer will vacate it, relocate elsewhere and continue to spam. (This is the origin of the term ‘whack-a-mole’, a term the anti-spam industry borrowed from the carnival game. As soon as you whack one mole (or spamming bot), it hides and another pops up.)
And therein is the problem of IPv6. An IPv4 IP address consists of four octets and each octet is a number running from 0–255. This means that there are 256 x 256 x 256 x 256 possible IP addresses, which is 4.2 billion possible IP addresses (in reality, there are fewer than this because there are many ranges of IPs that are reserved and not for public consumption). Using our formula above, if you had to list every single IP address singly in a file, then the size of the file would be 61GB. There are few pieces of hardware that can handle that size of file in memory (whether you are doing IP blocklist look ups in rbldnsd or some other in-memory solution on-the-box). Processing the file and cleaning it up would take a very long time; you simply couldn’t do it in real time where IP blocklists need to be updated frequently (once per hour at a bare minimum).
IPv6 multiplies this problem. We have seen that spammers already possess the ability to hop around IP addresses quickly. They do this because once an IP gets blocked, it is no longer useful to them. However, in IPv4 there are only so many places they can hide – 4.2 billion. In IPv6, though, there is virtually unlimited space in which to hide. To put it one way, there are 250 billion spam messages sent per day. Under IPv6, spammers could send out one piece of spam per IPv6 address, discard it and then move on to the next address for the next 10,000 years and never need to re-use a previous address. A mail server could never load a file big enough even for one day’s IPv6 blocklist if spammers sent every single spam from a unique IPv6 address. Because spammers could hop around so much, IP blocklists would encounter the following problems:
They would get to be too large for anyone to download, process and upload.
They would be latent since by the time an IP was listed, spammers would have discarded it and moved onto the next IP address.
This is why no mail receivers are thrilled about the idea of using IPv6 to send mail. (Other readers will point out that the major reason it won’t work is because a server could never cache that many IP addresses. While true, not every mail server looks up IPs on a blocklist via a DNS query.) They have to allow for the worst case scenario, which is that spammers will overwhelm their mail servers and drain processing power by having to deal with a tenfold increase in traffic.
One idea is to use whitelists instead of blocklists – block all mail from everyone and then maintain a central whitelist of good mail servers that send legitimate mail. The weakness here is that it defeats the whole purpose of email – that you can receive messages from people you haven’t heard from before. This is known as the introduction problem. New mail servers are brought up all of the time. There’s no way for you to know about it and the process of having to opt people in is a pain. This idea could be centralized, but what are considered legitimate mail servers for some people will not be legitimate for others.
Another idea is to take an unmanageable problem and break it down into a manageable one. Let’s go back and take a look at how CIDR notation works and how blocklists take advantage of them. Consider the IP 216.32.180.16. This can be broken down into four eight-bit octets, and then combined to make one 32-bit number:
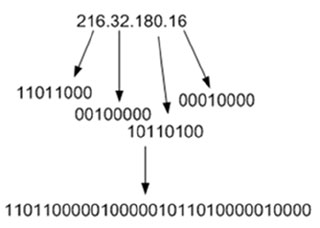
A CIDR range operates on the bits of an IP address. An IP address is said to fall within a CIDR range if the first n-bits of an IP address are the same as the first n-bits of the range (where n is a number between 0 and 32). For example, let’s take the range 216.32.180.0/24. If we convert this down to the bits that it represents, then this says include the range of IPs of any IP address that contains the first 24 bits; the ‘/24’ says to take the first 24 bits:
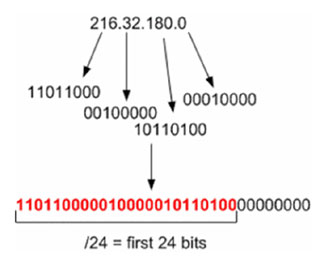
216.32.180.16 is said to fall within the range 216.32.180.0/24 because the first 24 bits of the 32-bit representation of 216.32.180.16 is the same as the first 24 bits of 216.32.180.0/24:

The first 24 bits match, but the last eight do not (illustrated by the ‘1’ in green). However, this doesn’t matter because we only need to match the first 24 bits. The red and blue parts match up and therefore 216.32.180.16 falls within the range of 216.32.180.0/24. If we take a slightly different IP address, 216.32.181.16, that will have a different 32-bit representation. It will not fall into the /24 range because the last bit does not match:

You can see that specifying things in CIDR notation is a very quick and easy way to list IPs on a blocklist. It makes sense to us humans reading it because we can interpret the numbers ‘naturally’, and it works from a technical perspective because it translates into bit-mapping. This is how PBL and other lists are able to manage so many IPs. The IP range 65.55.0.0/16 lists any IP that matches 65.55.xx.xx (65,536 IP addresses). They all fall into a logical range.
The number of IPs that fall within a CIDR range is evaluated as 2^(32-n) where n is the CIDR range (the number after the slash). A /24 (pronounced slash 24) is 2^(32-24) = 2^8 = 256 IPs, a /12 is 4,096 IPs, and so forth. The larger the CIDR range number n, the smaller the range of IPs it covers. To newbies, this is counterintuitive and takes a bit of time to get used to, but after a while you pick up the lingo. The smallest IP range is a /32 (one IP) whereas the largest is a /0 (every single IP).
IPv6 changes things because there are 128 bits in an IP address. Here’s an example from Wikipedia (Image taken from http://upload.wikimedia.org/wikipedia/commons/7/70/Ipv6_address_leading_zeros.svg):
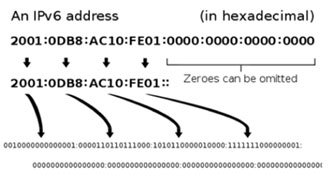
A /32 is no longer the smallest IP range, it is now /128. The size of a standard subnet is 2^64 IP addresses, the square of the size of the number of IPs in IPv4. While the planners of IPv6 don’t think that the entire address space will be used, it will make network routing and management much more efficient.
One idea to make the problem of mail more manageable is to restrict the address space that is allowed to send mail. Ideally, we’d restrict where mail servers could send mail from. If we say that the number of individual mail servers in the world will never exceed 32 million (not unreasonable), or 2^25, then what if the 25 least significant bits were reserved for mail servers?
Right off the hop, any IP address that tried to connect to a mail server to send email that was outside the range (in hexadecimal) of 0:0:0:0:0:0:0:0 to 0:0:0:0:0:0:0200:0000 (or, :: to ::0200:0000) could automatically be rejected. This would be a PBL in reverse. Whereas PBL lists IPs that should never send mail, this algorithm would state that mail should only be accepted from IPs that are allowed to send it, and everything else should be rejected.
This is similar to the idea of moving to a whitelist solution – in which mail is only accepted from the servers from which you want to receive mail. It solves the introduction problem because new people who you might want to hear from will be sending mail from a permitted set of IP addresses. All of the standard reputation tracking applies and the amount of space that spammers can hide in is restricted. If they want to send spam from servers that traditionally never send mail, they won’t be able to do it because all of the good guys have already set up an agreement that says ‘If you want to send mail to us, you must do it from this set of IP addresses.’
Randomizing the IP to send from a mail server that is outside the pre-agreed range will not make it easier for a spammer to hide because they wouldn’t have been able to send mail from it anyhow. To make an analogy, if you send mail from an IP on the PBL and then switch to another IP on the PBL, it doesn’t matter because in either case, your email would still be rejected.
As it turns out, the least significant 64 bits are reserved in IPv6. The first 64 bits of the IPv6 address are the network address (48 bits routing prefix and 16 bit subnet id), and the last 64 bits are the interface identifier. The 64-bit interface identifier may be generated automatically from the interface’s MAC address using the modified EUI-64 format, obtained from a DHCPv6 server, automatically established randomly, or assigned manually (because the MAC address of the machine is used to generate the interface identifier in some cases, this makes it easier to reject mail from these servers). You are no longer blocking an IP address that is subject to change in the case of DHCP, but instead blocking the actual piece of hardware which cannot change its MAC address. It’s a more granular level of block that is more reliable… if we can determine that the IP was generated using the MAC address). Using the least significant 64 bits will be problematic because an IP address is what we use to identify a device attached to the Internet and if they are already predefined by some algorithm, then we can’t use them. The least 25 bits in an IPv6 address are already spoken for. But, we could allocate some other 32 million or so IP addresses (a /103) somewhere to be used for sending mail.
This would have to be managed to avoid it spiralling out of control – we need to know which block of IP addresses are reserved for sending mail and then how to share that range across millions of customers. For example, suppose we had 1,024 IP addresses to allocate and we decided to reserve 500–564 (1/16 of the Internet) for sending mail. How do we share it? Let’s suppose that there are 10 major regional Internet registries (RIRs) who hand out the IPs to their customers (ISPs, people with their own home Internet permanent connections, businesses, etc.). Let’s further suppose they decide to divide it up manually. RIR 1 gets addresses 0–99, RIR 2 gets 100–199, and so forth up to RIR 10 who gets 900–999 with the final 24 IPs being reserved for special functions. However, RIR 6 has all of the IPs that are permitted to send mail. That’s not fair and nobody would agree to that.

Instead, we decide to divide things up more equitably. RIR 1 gets addresses 0–99 plus 500–504 (five IP addresses used to send mail). RIR 2 gets 100–199 plus 505–509 (also five IP addresses). Thus, each of the registrars has to ‘logically’ manage both its allocated range and its special email range. Instead of using CIDR ranges to allocate everything sequentially, there has to be a big table of who owns what. This gets very messy when you have to manage a lot of different IP ranges, particularly when the universe is as vast as IPv6. On the other hand, we’re going to have to manage lots of IP addresses anyhow and this is just one more set of IPs that must be managed.
If IANA were to publish the rules and say that these are the designated IP ranges that are to be used to send mail, then everyone would be playing by the same set of rules right from the beginning. Not only that, but it’s really not all that different from today. Regional Internet registries already allocate space to local Internet registries (LIRs), who then distribute the blocks down to their customers. When IANA provisions space, it would have to ensure that it provisions it such that it takes the special reserved range for mail into account. This is something that it already does today when it provisions IP space as well as geo-allocates it. Smarter people than me will need to figure out the necessary algorithms.

From these examples, it’s clear that using an even distribution based upon numerical order is not going to work but reserving IP ranges and then mapping them out would. Even today, we have reserved IP address space that nobody is supposed to use (224.0.0.0 upwards is reserved for multicast, 10.0.0.0/8 is part of RFC 1918’s internal address space, and so forth). The work that needs to be done is the following:
A committee of people must figure out how many IP addresses should be reserved for sending mail – such that we are not likely to run out of space in a couple of decades – and then reserve an appropriate range for it.
IANA must then reserve that space and come up with rules for how to hand that out to the RIRs. The RIRs must then come up with rules for how to allocate it to the LIRs, who then have to figure out how to allocate it to their customers. They then have to manage the infrastructure necessary to maintain the mappings of who owns what.
Next, RFCs need to be written on how to send and receive mail over IPv6.
Then, software vendors need to write code to perform IPv6 email transactions that are able to implement these rules.
Finally, IP blocklist maintainers need to start populating their lists in IPv6 notation pursuant to the restrictions that are built into the RFCs.
It’s a ton of work – years of it – but if we want to start receiving mail over IPv6 then that’s what needs to be done.
This restriction of IP space for mail solves one problem but it doesn’t solve others. On the one hand, it makes management of IPs scalable for machines that are bots. Today, most spam is sent from botnets. However, botnets do not always send out all of their spam directly – many bots compromise legitimate mail hosts or email accounts and send out spam that way, or create a throwaway account at a free email service and send out small amounts of spam from it before discarding it. This technique is used today but on a smaller scale than spamming directly. If we successfully solve the problem of direct-to-spam botnets, spammers will simply shift the bulk of their spamming to compromised or throwaway accounts.
I guess that means those of us in the e-security industry will always have a job. There’s a silver lining to everything!
[1] Levine, J. A Politically Incorrect Guide to IPv6, part III. http://jl.ly/Internet/v6incor3.html?seemore=y.
[2] Leiba, B. IP Blocklists, Email, and IPv6. http://www.circleid.com/posts/ip_blocklists_email_and_ipv6/.