2010-12-01
Abstract
Sender authentication is a hot topic in the world of email. It has a number of uses and a number of suggested uses. Which ones work in real life? Which ones don’t quite measure up? Can we use authentication to mitigate spoofing? Can we use it to guarantee authenticity? And how do we authenticate email, anyway? Terry Zink provides the answers to these questions and more, this month focusing on the main technology used to digitally sign emails: DKIM.
Copyright © 2010 Virus Bulletin
In the last article in this series (see VB, September 2010, p.17) we looked at digital signatures and how they enable the contents of a message to be encrypted, effectively allowing one to sign a message and take responsibility for it by validating the identity of the sender. In this article, we look at the main technology used to accomplish this in email.
Domain Keys Identified Mail, or DKIM, is the main technology used to digitally sign a message (DKIM is specified in RFC 4871). It is the successor to Domain Keys, which was developed by Yahoo! in 2003. There are already several tutorials available that discuss the finer points of how DKIM works, so this will be a quick discussion.
Tony’s organization owns the domain tony.net. Tony generates a pair of keys – a public key and a private key. The public key is published in DNS and the private key remains under Tony’s control. He has written an application such that every piece of mail that goes out from his mail servers has access to this key. An email he wants to send contains the following:
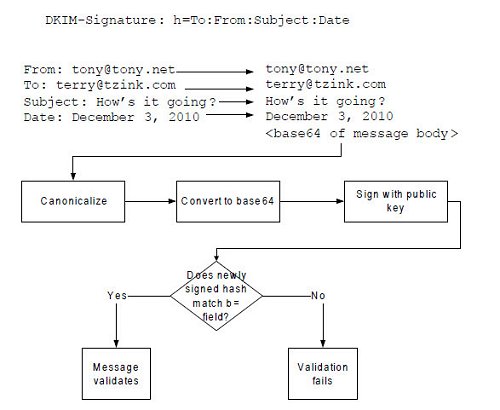
From: [email protected] To: [email protected] Subject: How’s it going? Date: December 3, 2010
Tony picks what authoritative domain will sign the mail (in this case, tony.net).
Next, Tony’s mailer picks what fields to sign in the message. Commonly signed fields include the Message-ID, Date, From (which is required), To, Content-Type and the contents of the message itself. With the exception of the contents, all of the fields that are signed are appended together (more on this later) and are called out explicitly in the h= field. Thus, on the other end, the receiver can look at this field and know exactly what fields to extract in order to verify the DKIM signature.
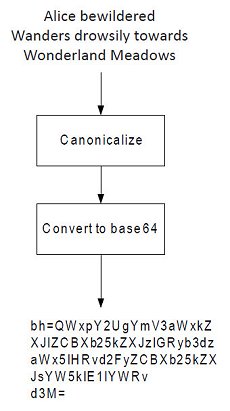
Tony prepares to sign his email message with DKIM. The first step is to hash the body contents in base64 encoding and insert it into the bh= field. However, DKIM provides two options for hashing content in the message: using the relaxed canonicalization algorithm, or using strict canonicalization.
Using strict canonicalization means that the data is presented and signed as is, whereas relaxed canonicalization folds white space. You can also specify whether or not the data in the headers uses the strict algorithm, and whether or not the data in the body is signed using the strict algorithm.
Why does this matter? It matters because email has a habit of being modified in transit, and some MTAs have a habit of tampering with the contents of a message. Suppose you wanted to generate a hash of the following message:
Alice bewildered Wanders drowsily towards Wonderland Meadows
This piece of text contains seven words, four spaces and two line breaks. Each character in the message corresponds to a different value when it is encoded in ASCII text. A space is ASCII character 20, whereas a carriage return (a line break) is ASCII character 0D. So, the piece of text is signed by transmitting using the ASCII characters and a hash value is created.
Relaxed canonicalization folds all multiple white spaces into a single white space and all line breaks are also folded into a single white space. Our example above becomes the following:
Alice bewildered Wanders drowsily towards Wonderland Meadows
All of the ASCII 0D characters have been replaced with ASCII 20 characters. This means that if a message is hashed using base64 encoding, the second version of the text will have a different hash value from the first.
Some MTAs will wrap line breaks in the message headers. For example, the Content-Type header might be split across two lines. When going through an MTA, those line breaks might be folded to put them all onto one line. If you sign a message using the strict canonicalization algorithm, taking a hash of the header split across multiple lines, and then the MTA wraps the line breaks, the receiver will not be able to verify the signature because the message that was signed will be different from the one that they see. The receiving MTA will not know that the message was modified in transit, so when they attempt to validate and this fails, they will assume that the message has failed validation.
The canonicalization algorithm used by the mailer is specified in the c= field. Generally speaking, I recommend that mailers use the relaxed header canonicalization. If an MTA folds white space and line wraps into a single line, then it does not matter. The receiver is supposed to fold line wraps anyhow, and therefore they will still be able to validate. The relaxed algorithm is more flexible and resilient.
Next, the fields from the headers Tony chose to sign with are appended to each other, along with the bh= field, and then canonicalized. The post-canoncicalized message is converted to base64, and then this is signed using an encryption algorithm (usually rsa-sha256) with Tony’s private key. It is this signing with the encryption algorithm and private key that gives DKIM its digital signature.
The result of the signature is put into the b= field (see Figure 2).
The DKIM-Signature header is then constructed (this is not an exhaustive list of the fields, only the mandatory ones and some common ones):
The algorithm that is used is specified using the a= field.
The signing domain is specified in the d= field.
The selector is specified in the s= field. The signing domain is frequently the same as the value in the SMTP MAIL FROM but they do not have to be the same. You could have two different values in the s= field and the FROM field. The s= field tells the recipient where to look up the message in DNS to get the key.
The headers that are signed are specified in the h= field.
The time of signing, in Unix time, is specified in the t= field.
The hash of the body contents is specified in the bh= field.
The digital signature is specified in the b= field.
The message has the header inserted and then it is sent as an outbound mail.
DKIM-Signature: v=1; a=rsa-sha256; c=relaxed/relaxed; d=tony.net; s=s1024; t=1288392329; bh=QWxpY2UgYmV3aWxkZXJlZCBXb25kZXJzIGRyb3dzaWx5IHRvd2FyZCBXb25kZXJsYW5kIE1lYWRvd3M=; h=To:From:Subject:Date; b=FKgi…MFT/=
Now, as a receiver, here is the process that I take to validate the message:
I receive the email and see that the message contains a DKIM-Signature header. I look for the s= field and extract s1024, and look for the d= field and extract tony.net. I use this to look up the public key in DNS. The field that I query is the following:
<selector>._domainkey.<domain>
In this case, I look up the public key for s1024._domainkey.diamond.net. I do not look up the domain mentioned in the From: field or SMTP MAIL FROM.

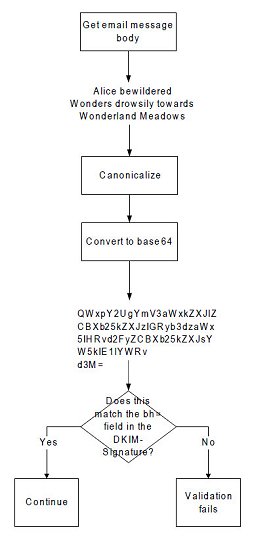
Next, I take the message body and canonicalize it using the algorithm specified in the c= field. I compute the base64 hash of the message and compare it to the value in the bh= field in the DKIM-Signature.
The next step is to extract all of the header fields in the h= field, combine them with the hashed body content, and then create a base64 hash of the message using the specified canonicalization mechanism.
This new base64 hash can be signed with the algorithm specified in the a= field using the public key that was retrieved from DNS. If it matches the contents of the bh= field, the message is validated. If it does not match, then the message is not validated.
This is the sequence for validation. The matching of the hashes using the public key prevents any spoofing. The stronger the signing algorithm, the more resistant the message is to being spoofed by a brute force attack of guessing the public key.
The basic advantage of DKIM is identifying a sender’s identity, and being able to validate that identity with confidence. It is nearly impossible to spoof DKIM; if someone is validated using DKIM then you can be sure that the mail came from the sending domain specified in the d= field.
Identity is useful for whitelisting, but that is not DKIM’s only application.
DKIM’s strength is that it does not tie an organization to a particular set of routing in the way that SPF and SenderID do with regards to forwarding. A message can be transmitted and take any number of paths to get to its receiver. It can be forwarded once, twice, three times or more, and as long as the message is received intact, it can still be validated.
Both SPF and SenderID protocols specify that the connecting IP address should be used for validation, but if mail is forwarded, this breaks both protocols because the sending IP is not the same as the connecting IP.
With DKIM, this doesn’t matter. The DKIM-Signature header contains all of the necessary information and it doesn’t rely on IP addresses. All that is needed in order to validate a message is contained within the header itself. If neither the header nor the body have been modified in transit, then the message can go through any number of hops and the validation will be unaffected. Rather than comparing the sending IP you look up the sending key in DNS. DKIM effectively says ‘Hey, here is what you need to use in order to validate me. That’s all you need. Now get cracking.’
Where DKIM comes in especially useful is in identifying the source of a message when you really want to identify the source regardless of its originating IP. One problem today is the lack of IPv4 space. We are running out of IP addresses that use four octets and that is why IPv6 was developed. But for the foreseeable future, we are going to be using IPv4, and organizations that use IPv6 will likely end up taking email from IPv6 and translating it to a shared IPv4 IP address before sending email out to the Internet.
What we have is a scenario where we will have many different organizations using a common IP address out of necessity. There will be a mixture of mail coming from that single IP address – some of it will belong to organization A, some will belong to organization B, some will belong to organization C, and so forth. Each organization will have a different kind of mail – organization A may send political messages, while organization B may send only one-to-one communication, and organization C may send marketing messages. None of these organizations will particularly want to share sender reputation with the others, but most receivers will see the mail coming out of that IP as a single resource, despite it being shared in reality.
DKIM allows a receiver to move from a model of IP reputation to domain reputation. An IP might have a poor quality of mail, but some senders using that common IP resource might actually be good. By knowing who the sending domain is, it is possible to discard all mail from a particular IP except for one or two particular organizations. IP reputation is effectively a short cut for mail filtering; by maintaining a large list of good and bad IPs, email receivers can save bandwidth and processing resources and reject mail much more quickly in the process. However, although mail receivers would really like to perform domain reputation checks, since the SMTP protocol allows anyone to send mail as anyone else, a receiver cannot trust the domain in the MAIL FROM. DKIM allows a receiver to trust the sending domain instead of the sending IP. As unique IP addresses become increasingly rare, relying on IP reputation is going to become less and less reliable as senders will be forced to inherit the same IP space. However, they will not be forced to share the same domain reputation. Organizations will be able to come up with any domain they want, and as long as we all know which domains we want to talk to, we will be able to use that to differentiate between senders.
The example I used in part 3 of this series when discussing SenderID (see VB, August 2010, p.15) is the situation in which a large organization requests another mailer to send mail on its behalf. In this case, one domain might appear in the From: address (so that is what is displayed to the end-user), while the SMTP MAIL FROM is different. This confuses spam filters that implement SenderID. Organizations that do this can also end up sharing the reputation of others that utilize the same IP address. When an organization is trying to protect its brand, it might not want to share the reputation of others.
With DKIM, you do not need to share the reputation of the sending IP. In fact, you can very reliably build up the reputation of a sending domain that takes explicit responsibility for a message.
What a receiver can do is build a domain reputation table not of the domain in the From: address, but instead of the domain in the d= field. Because the domain in the d= field is tied to the actual sender of the message by being cryptographically tied to the domain in DNS, it is not spoofable. The only entity that could send that message is the domain in the d= field.
An organization that sends mail on behalf of someone else puts the domain on whose behalf they are sending in the From: field, and their own domain in the d= field. When the receiver gets the message, if it is validated they build up the reputation of the domain in the d= field. The From: field can be spoofed, but the d= field cannot. If the domain in the d= field has a good reputation, then mail from it can be fast-tracked and delivered. If it has a bad reputation, it can be marked as spam.
As good as DKIM is for validating the source domain of a message, the reality is that it is useful in some contexts and less useful in others.
DKIM proponents are quick to point out that all it lets you do is identify a sending domain for a message authoritatively. That’s all it does. SPF and SenderID let you do this as well, but SPF and SenderID also let you detect spoofing.
The down side of DKIM is that, while it allows you to validate an identity positively, it does not allow you to negatively validate (invalidate?) an identity – that is, to detect spoofing.
If you get a message with a DKIM-Signature and it fails validation, you are supposed to treat the message as if it had no DKIM-Signature at all. Whereas SPF and SenderID allow you to specify that failure to validate is the same as non-permitted spoofing, DKIM says no such thing. There are three reasons why DKIM does this (I don’t speak for the authors of DKIM, this is based on my personal observation of mail filtering):
A message without a DKIM signature is not indicative of spoofing. One basis for this is simple: if you receive a message without a DKIM signature, how would you know that the message was supposed to be signed? In DKIM, the instructions are contained within the DKIM-Signature header. Specifically, you look up the s= field for the selector, and the d= field for the domain. Combining these, you then query DNS to look up the public key.
However, a message that contains no DKIM signature contains no instructions. How do you know what the selector is? How do you know what the author domain is? You don’t. You could guess that the author domain is probably the same as the From: address, but you still wouldn’t know what the selector was for the domain. Thus, if you received a message from [email protected] and you had never received mail from that address before, how could you know that it always signs mail with DKIM? If there was no DKIM signature, you couldn’t because there are no instructions in the mail telling you what the author domain is and what the selector is. Thus, an illegitimate message with a spoofed sender looks no different from an unsigned message.
Email gets modified in transit from time to time. Lines get wrapped, footers get inserted and date stamps can be changed when they are sent through a relay. For this reason, a message with a DKIM signature that doesn’t validate might be spoofed, or it might have changed slightly between the time it was sent and the time it was received. These small changes do not materially affect the contents or interpretation of the message; it certainly hasn’t been spoofed. However, it prevents the message from being digitally validated and therefore it cannot be trusted as actually coming from the source from which it purports to have been sent. The fact that a DKIM signature cannot be validated means nothing more – you don’t know why it couldn’t be validated.
DKIM requires the maintenance and deployment of private keys across all of an organization’s outbound mail servers. For organizations that send all of their mail from one place, this is an easy infrastructure to maintain. For organizations that send from multiple sites – such as a global company with different IT departments that set their own policies – it is more difficult to coordinate. Thus, some departments in the United States might sign with DKIM, while another in the Czech Republic might not. Because of the realities of infrastructure maintenance, the lack of DKIM stamping cannot be indicative of spoofing. (SPF and SenderID have the same problem, but the authors of DKIM decided to work around this by relaxing the failure case of DKIM.)
The DKIM protocol is used to identify a sender. Unlike SPF and SenderID, it is not used to detect spoofing.
This is a blocking issue for deployment for mail receivers from a cost/benefit ratio perspective. Most mailers are already doing their best to drive down the rate of false positives (FPs). They maintain large whitelists and are forever doing what they can to tweak their content filters by trading off anti-spam effectiveness against fewer FPs. Unfortunately, spammers are always trying to game spam filters – always. One of the techniques that they use is to spoof the sender domain, and this tricks users into taking action that they might not otherwise take. From an email receiver’s perspective, here is how they see the spam problem:
Spam accounts for 90% of the mail that they see and it is the biggest problem they need to tackle. Spoofed mail is a substantial part of the spam problem that they need to solve.
False positives are a problem in general, both for signed and unsigned mail. However, anything that is done to drive down FPs in the unsigned mail scenario also helps with the signed mail scenario.
DKIM allows the receiver to drive down false positives by fast-tracking mail for identities that they can validate and want to hear from. Thus, in theory they can be more aggressive on other types of mail. Unfortunately, this Holy Grail is forever elusive because being more aggressive on other mail means a higher false positive rate on unsigned mail, and that generates user complaints. Thus, the proper use of DKIM is only for fast-track filtering of validated senders you want to hear from, and the aggressiveness should be left alone on all other types of mail.
Thus, DKIM somewhat improves a false positive problem by narrowly helping the avoidance of some FPs, but you could get similar results by making the filter less aggressive. However, the problem of spoofing still exists and users generate a lot of complaints when they see spoofed mail in their accounts. So, from a spam filtering point of view, DKIM doesn’t address the spam problem at all and the false positive problem can be addressed in other ways.
DKIM does require more processing overhead than SPF and SenderID, and also requires DNS queries and computing hashes on the receiving side. This adds computational cycles. On the sending side, it requires the management of keys deployed across a wide array of infrastructure, and these keys must be updated periodically. Key management across a large organization is not a trivial task.
Thus, mailers who implement DKIM are very cognizant of the fact that DKIM is useful in certain niche scenarios. It allows you to do some things, while not really getting more mileage out of others. Spam filterers are forever trying to keep spam out of people’s mail boxes and if a content filter says that a message is clean, it should be passed through to the end-user. You don’t really need DKIM for that if your filter is accurate enough.
On the other hand, many filters today don’t use email and assign only a binary spam/non-spam decision. If a message is non-spam and it is from a trusted source, then perhaps the message can be richly rendered in the user’s mail environment. For mail from untrusted users you might not want to display all of the links and images, but for mail from senders/domains with a good reputation it is safe to do so. Rather than maintaining a list of good IP addresses, you could maintain a list of domain names. Since domains are closely associated with brands (e.g. paypal.com, amazon.com), and because IP space can change, it is theoretically simple to manage if it can be done securely.
On the other hand, all is not lost when it comes to DKIM, spoofing and malicious intent. The DKIM protocol does address it in an addition to the RFC called ‘Author Domain Signing Policies’. The discussion of that, however, must wait until the next article in this series.