2010-04-01
Abstract
While accepting the increasing importance of behavioural analysis and detection, Gyozo Papp looks at how current detection technologies, from the simplest to the most complex, can be backed up by pattern matching, proving that it is a mature technology that is very much alive.
Copyright © 2010 Virus Bulletin
The title of this article echoes the sort of conversation that might take place between a security industry PR rep and a traditional anti-virus programmer. While accepting the increasing importance of behavioural analysis and detection, this article looks at how current detection technologies, from the simplest to the most complex, can be backed up by pattern matching, proving that it is a mature technology that is very much alive.
First, I must make a confession: I am not a virus analyst; I am a regular developer in an anti-virus company. Before that, I was involved in web technologies and I knew very little about malware and malicious content. I have been working in my current position for six years, during which time I have witnessed a technological revolution as the industry moved from signature-based detection to behaviour-based detection and cloud computing. However, I was still uncertain as to what the phrase ‘signature-based detection’ really meant and why it was said to have been superseded (or was simply ‘dead’), while pattern matching continued to evolve in script languages.
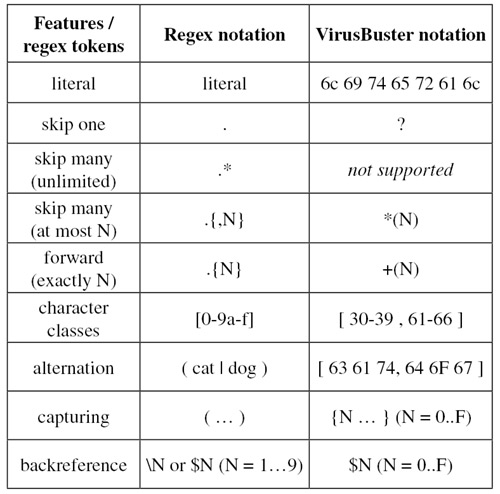
The definitions of the term ‘anti-virus signature’ in web encyclopedias go like this: ‘a unique string of bits, or the binary pattern, of a virus’ [1], ‘a characteristic byte-pattern that is part of a certain virus or family of viruses’ [2]. The term ‘pattern’ was what helped me understand this technology. The word ‘signature’ describes a possible set of byte variations derived from the common traits of a set of samples. There is quite an obvious analogy between signatures and regular expressions (regex): ‘a regular expression is a pattern describing a certain amount of text’ [3].
The power of regular expressions lies in metacharacters (nonliteral tokens) which do not match themselves, but which define rules as to how to match other tokens in a piece of text (see Figure 1). In the early days, an indifferent character could be skipped (this was only a single byte), then a couple of them could be skipped at the same time (as repetition operators or quantifiers were introduced), and later more specific variants were introduced (character classes, alternation).
The next fundamental add-on was the concept of memory registers or variable support. So-called ‘capturing’ can store arbitrary content from a string so that it retains its flexibility. ‘Backreference’ can only match this stored content, therefore its accuracy is greater than that of simple wildcards. These were enough against simple virus variants. Figure 2 illustrates how capturing and backreference work.
A closer look at Figure 1 reveals some minor deviations in our notation from normal regex implementations. The most apparent is that regex engines are character-based, because they are used almost exclusively in text processing. With the advent of Unicode, the terms ‘character’ and ‘byte’ (octet) stopped being interchangeable. However, malicious content still spreads in machine code, and therefore our grammar is still byte-based (see Figure 3). The most frequent repetitions (skips) earned special notations based on their analogy with shell wildcards (e.g. dir *.exe). It is worth noting that regex quantifiers and wildcards are not the same. The former can repeat any arbitrary expression, while the latter embodies a repeatable fixed expression, the dot (.) matching arbitrary bytes. As a consequence, wildcards can work with fewer backtrack states. However, scanning in a text-based context demands real quantifier support.

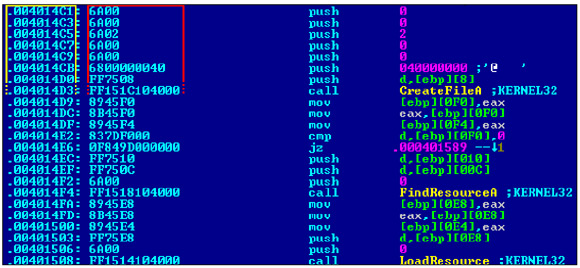
Figure 3. Byte sequence captures buffer size which is referred to later entering a loop. The bitmask (B?) proves to be extremely useful when dealing with register encodings in x86 opcodes.
On the other hand, VirusBuster notation circumvents the most painful legacy of early regex implementations, which happened to use parentheses for two different purposes: grouping (mostly expressing precedence) and capturing [4]. Our grammar defines separate symbols and supports named capturing only, i.e. the capture must declare which variable to fill in.
However, there are subtle differences under the hood. While a regex engine matches one pattern (or at most a few) against arbitrary lengths of text at a time, a traditional AV scanner does almost the opposite. It has to check if any of countless signatures can be found anywhere amongst thousands of files. The great divide in the number of signatures, matching attempts and the various sizes of input results in a radically different implementation.
Neither the number of files nor their characteristics are under our control, and the proliferation of signatures was not curbed effectively. So we found that the only way to retain performance levels was to reduce the number of superfluous matching attempts or at least the time wasted on evaluation of such. Literal bytes prevent a signature from matching virtually anything because literals are the least flexible parts of a signature. If they do not match at a given point, the signature as a whole will fail. We exploited this fact, in addition to more advanced text search algorithms [5]. The sooner the less flexible token is matched, the sooner the attempt is terminated.
In order to achieve this, signatures must be converted to start with as many infrequent literal bytes as possible. The rewind wildcard (-(N)) was previously introduced into the grammar for the purpose of similar manual optimizations (Figure 4). It makes the engine skip backward in the target string, thus -(N) can be considered the opposite of +(N). Moreover, a fairly simple transformation based on this rewind token can move any literal from the middle of an arbitrary complex pattern to its beginning. The real revelation was that this transformation can be automated quite easily, so we were able to benefit from it without the need to modify a signature by hand. Byte prevalence statistics were aggregated from several typical desktop environments to define the most infrequent sequence candidates. The overall engine speed improved by 30%, surpassing our expectations.
The combination of rewind and skip wildcards may combat spaghetti codes where malicious code is split into small blocks, shuffled and bound together using jump instructions. The physical layout in the file and the runtime trace of the instructions differ so much that it is commonly believed that ‘detection signatures on this kind of code are not efficient at all’ [6]. Figure 5 demonstrates the basic idea of how to write a signature that matches the code blocks in question regardless of their actual order. The exact order and the distance of X from Y may vary from sample to sample, but a single signature with the appropriate limits may match all. As the number of code blocks increases, the number of possible layouts grows exponentially, so other (pattern) constructs should be taken into consideration.
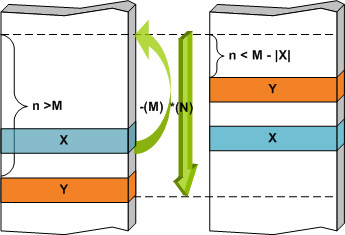
Figure 5. X-(M) *(N) Y: position-independent fragments in spaghetti code. N can be considered the diameter of the ‘spaghetti plate’.
The example in Figure 6 shows another use of this technique in generic detection where a couple of string constants can be matched. Just one of these snippets would not be sufficient to indicate a threat, but their collective occurrence in a narrow range should raise suspicion. We will see how the signature is strengthened further in the next section.
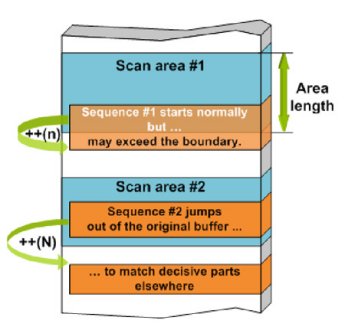
An AV scanner usually does not scan the whole file; instead, in the hope of better performance and fewer false positives, it restricts signature detection to specific areas of the file where there is more chance of malicious content being found. This is the reason why unlimited repetition is not supported in our grammar. Of course, sometimes the text being searched within is also adjusted before applying a regex. The significant difference lies in the time frame. In the case of regex, preprocessing is presumably carried out right before the matching, being aware of the actual needs. In contrast, the boundaries of the scanning areas in the AV engine are predefined, based on previous experiments, and can be changed slowly according to the required software modification.
However, occasionally the search may have to be extended beyond these limits. Generic detections often stumble because randomly inserted junk bytes displace valuable bytes from the scanning area. The suspicion generated by the string constants in Figure 6 is confirmed by the malicious opcodes from the end of the scan area. Since the chances are that the actual code block is slipping away, the short forward skip (+(20)) is replaced with a reload command to ensure that the rest of the signature stays in the scanning buffer. Check the difference between the offsets outlined in yellow.
In other cases a brand new segment of a file should be scanned for specific sequences, for example because a new file infector is spreading in an uncovered area or if a file format which is rare or unknown to the current engine version has to be supported.
Both demands can be satisfied with reload functionality (Figure 8), an idea borrowed from Perl Compatible Regular Expression (PCRE) Library [7]. The reload tokens generate an interrupt toward the pattern matching module to check if the rest of the signature exceeds the boundaries of the current scanning area. If so, the engine tries to find the requested position in the source stream being scanned, which is the file or emulator’s virtual memory in the simplest cases. If it fails, the rest of the signature cannot match and the signature is discarded immediately. Otherwise, it loads the requested number of bytes into the scanning buffer and continues the matching with the next token. The three reload tokens are extensions of the basic forward and rewind tokens (++(N) and --(N)) for relative positioning (Figure 9) and the special address token (@@(A)) to follow absolute addresses pushed onto stack or file markers. Figure 9 shows the exploitation of a PDF document in JavaScript where the payload is displaced due to the 4KB spray. The spray is still in the scanning area, so a signature, start matching the spray and then reload, may succeed.
In Figure 10, a single skipped byte (+(1) or ?) is substituted for the reload token (++(1)) to ensure that enough bytes will be loaded into the scanning buffer and thus all three shuffled code junks can be matched in it. The skipped byte is the least significant byte of the target address of a CALL/JMP instruction.
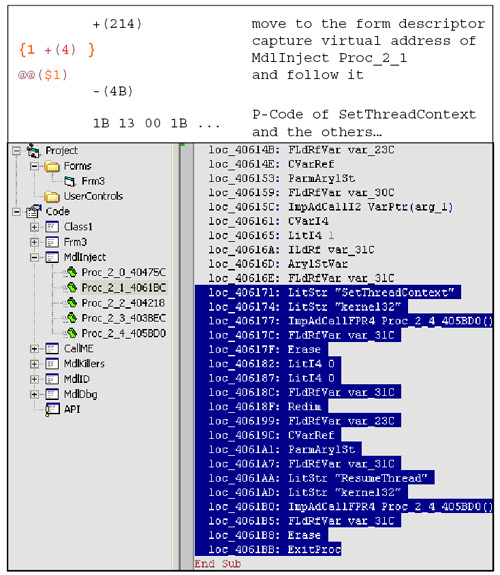
The combination of reload and capturing is also a particularly useful feature. If the positioning tokens (skip, forward, rewind and address) can accept captured variable content, it eventually enables the signature to parse and traverse low-level formats (Figure 11 and Figure 12).
According to the addressing mode of the x86 CPU family, at least the multiplication of captured offsets should also be implemented.
After this overview of recent signature grammar, take a look at more general definitions of signature-based detection: ‘A signature is a small piece of data which uniquely identifies an individual item of malware (…) Signatures can be made more flexible to allow for generic detection of similar items of malware’ [8]. So, a single signature may detect a large number of viruses. Admittedly, this kind of generic detection is less likely to be effective against completely new viruses and is more effective at detecting new members of an already known family. Still, its significance cannot be neglected in view of its reported efficiency [9].
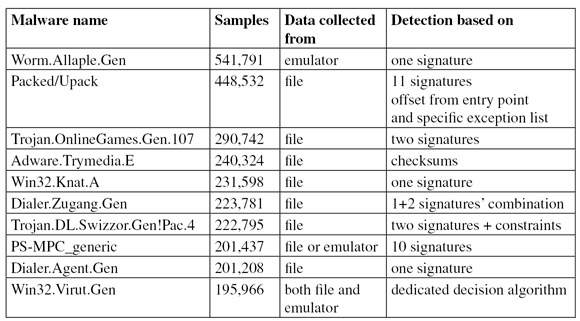
Figure 13 shows another interesting result of a more recent survey over our own malware collection. The vast majority of the top recognitions (i.e. those which detect the most samples) utilize signatures either on mere file fragments or on emulated data. Some signatures are considered strong enough to indicate the threat itself. In terms of numbers, three single signatures are responsible for detecting nearly one million samples, and about 30 signatures in certain combinations detect a tenth of our malware collection.
The main characteristic of pattern matching, however, is also its utmost weakness. It grabs the samples’ common traits at a very low, machine level, and therefore this technique is susceptible to modification (think of server-side polymorphism). This sensitivity sometimes comes in handy. Static decryption of polymorphic malware can be strengthened if a signature can provide valuable input for the decoder component. (Even when real decryption is not possible, other cryptanalysis methods can be backed by advanced pattern matching to extract other characteristics strong enough to form detection.) Let us consider the signature matching a decoder fragment shown in Figure 14.

Figure 14. The start and end offsets of the area to be decoded are captured and stored in the variable $E and $F, respectively. The number of iterations will be stored in variable $0.
These values locate the encrypted content, making brute force iterations and superfluous decrypting steps unnecessary; on the whole it streamlines the operation and probably speeds up detection. This data collection and propagation technique can be utilized throughout an AV engine. Besides cryptanalysis, database-driven unpacking may take advantage of it in order to boost emulation performance. During emulation, signatures identify substitutable code chunks which trigger built-in native implementations with proper parameters. This is also the primary source of input for malware-specific decision algorithms.
Beside the feature richness there are other benefits of reusing software components. When we were planning the Win32 API-based behavioural detection, it was revealed that the natural representation of an API trace was a regular log file. The two main tasks in this scenario were to log API function calls and search in them for malicious API trace fragments. The former was quite straightforward; emulator hooks sent messages to a textual log file for the sake of readability. From that point, the search resembled text processing which was also quite simple with the hairy old regex-like pattern engine. The first version of the test engine was built within a week and was ready to explore the capabilities and limitations of this behavioural-based detection method. The following week, the first API trace detections were written by our virus analysts against real malware samples.
Of course, the final version superseded the proof of concept in more fields. The entire API trace search was split into a high-level API call order component and a low-level API argument monitoring component. The API call order was matched by a dedicated binary algorithm for maintainability purposes. However, our regex-like grammar served the low-level argument matching needs entirely, which should not have been a surprise in the light of the aforementioned. It actually performs better since just-in-emulation-time argument checking replaced the concept of log file. The fact is that we could use pattern matching with or without text processing both effectively and efficiently.
How did we benefit from the early prototype? First, it elongated the research period which, in turn, allowed us to evaluate special cases like anti-emulation and anti-debugging, emulation flaws and other shortcomings in more depth. More feedback helped us design more prudently. Second, it meant that the research and development could work in parallel, which guaranteed that, despite its complexity, the project would finish in time. Finally, using a tested and verified component made the whole concept a more robust and mature technology, even from the start.
The limitations of pattern matching are plain to see, but you may also catch a glimpse of how far it can be improved. Even though hundreds of thousands of pieces of malware daily manage to evade signature detection and the concept of this reactive technology is no longer effective, the software component can be repurposed with success and numerous stunning features could be added to serve both static and dynamic detection methods better.
Nevertheless, regular expression is backed by the solid mathematical background of formal language theory. At the dawn of computer science, the term ‘regular’ was precise and adequate; it referred to the expressive power of the formal regular grammar (Type-3 grammars) in Chomsky’s hierarchy [10]. Although regex implementations still acknowledge this heritage in their names, they exceeded this strict limit quickly. We haven’t touched the conceptual details, but they can no longer be treated as regular grammars. Moreover, certain research and development [11] in this field looks very exciting and promising, especially, for example, parsing expression grammar [12]. A whole new generation of file format detections can be built on the top of that architecture which may have considerably shorter reaction time due to the managed code environment provided by such implementations. I think we should think twice before calling anything ‘dead’.
I would like to thank my colleagues, especially Gabor Szappanos and Robert Neumann, for their valuable feedback and helping me to understand how virus analysts squeeze out the most from the presented features.
[5] Navarro, G.; Raffinot, M. Flexible Pattern Matching in Strings. Cambridge University Press, 2004 reprinted (ISBN-10:0521813077).
[11] Parrot Grammar Engine: http://docs.parrot.org/parrot/latest/html/docs/book/pct/ch04_pge.pod.html.