2009-04-01
Abstract
'An even better solution is to be proactive in the cloud.’ Luis Corrons, Panda Security
Copyright © 2009 Virus Bulletin

Over the past couple of years we have been hearing the same thing over and again from multiple sources in the AV industry: that the amount of malware in existence is increasing exponentially. In 2008 AV companies were reporting more than 13 million malware samples and in March 2009, McAfee’s AVERT Labs announced that it had received its 20 millionth malware sample.
The announcement caught my interest so I took a look at our own database and found that we had approximately the same number: on 12 March 2009 it contained 20,064,146 confirmed malware samples.
There are a couple of explanations for this endless flood of new malware samples. First is the large number of point-and-click applications readily available on the black market. Cybercriminals can use these to create custom trojans and pack them without having to write a single line of code. This means that even those without programming skills are able to create new pieces of malware extremely quickly and in large numbers.
The second explanation is server-side polymorphism. When infecting machines in order to steal data, create a botnet, etc., why should the cybercriminals use the same binary code to infect, say, 10,000 computers? Almost every anti-malware solution relies primarily on detection signatures, and an effective way to defeat weak signatures is to make each file slightly different – thus a very efficient infection strategy is to infect every machine with a slightly different sample. This can be achieved with server-side polymorphism: a polymorphic engine resides remotely on a server and distributes mutated variations of malware in large volume. While this strategy won’t work against all technologies (for example it is ineffective against HIPS, advanced heuristics, generic detection etc.), it is well worth the effort for its ability to evade signature detection.
I was interested to find out whether these explanations could be verified by our detection data – for example to see for how long each threat was active. I decided to dig into the 2008 data in our database. I ignored MD5s in order to avoid bias caused by minor changes in the malware files, and instead focused purely on detections. I looked at detections over a time period from the 98th day to the 263rd day of 2008.
First, I calculated the total number of detections seen in each 24-hour period – regardless of whether we had seen each threat one time or one million times. Then I calculated the percentage of detections that were seen on that day only – of all the active detections seen each day, an average of 4% were not seen again.
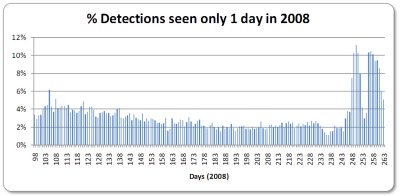
There is no doubt that the volume of malware has been increasing exponentially over the last few years. If 4% of the detected threats are active only for a period of 24 hours, detection must be proactive and as fast as possible. I believe that the fastest way to deliver knowledge is via the cloud, and a number of security companies are adopting this technology.
An even better solution is to be proactive in the cloud – taking advantage of the user community to detect malware that not even the cloud has seen before. This can be done by merging the proactive technologies available at customers’ endpoints with the cloud: as soon as a malicious process is detected in a user’s PC (whether by system heuristics, emulation, sandboxing or behavioural analysis, etc.), the rest of the users worldwide will automatically benefit from that specific detection. This results in a close-to-real-time detection, not only of initial malware outbreaks but also of targeted attacks whose objective is to infect a very small number of users and stay below the radar. I truly believe that this is the best AV companies can do right now, and I hope more will follow suit. Let’s see if we can build a safer world!