2008-12-01
Abstract
Alexandru Cosoi describes a method that attempts to deal with the phishing problem at the browser level, by combining both whitelisting and content-based solutions in a web page forgery detector.
Copyright © 2008 Virus Bulletin
Phishing can no longer be considered a new and emerging phenomenon. Fake websites impersonating both national and international financial institutions appear everywhere, trying to manipulate users into giving away their credentials. This article describes a method that attempts to deal with the phishing problem at the browser level, by combining both whitelisting and content-based solutions into a web page forgery detector.
Phishing is a form of social engineering in which an attacker attempts to acquire sensitive information from a victim by impersonating a trustworthy third party.
In a typical phishing attempt, a fake website (also termed a clone) poses as a genuine web page belonging to an online retailer or a financial institution, and the user is asked to enter some personal information (e.g. username and password) and/or financial information (e.g. credit card number, bank account number, security code etc.). Once the information has been submitted by the unsuspecting user, it is harvested by the attacker. The user may also be directed to a web page which installs malicious software (e.g. viruses, trojans) on the user’s computer. The malicious software may continue to steal personal information by recording the user’s keystrokes while visiting certain web pages, and may transform the user’s computer into a platform for launching other phishing or spam attacks.
Current anti-spam technologies have achieved competitive detection rates against phishing emails, but recently phishers have started using a number of different mediums to lure users to their fake websites – including instant messaging, social networks, blog posts and even SMS [1], [2]. Once attackers have some basic information about their victims from social network profiles [3], it is easy for them to socially engineer their way into the users’ trust. This makes it even more important for browser-level protection to prevent the user from accessing the malicious websites.
Current browser-based technologies employ whitelisting and blacklisting techniques, various heuristics to see if URLs are similar to well-known legitimate URLs, community ratings and content-based heuristics [4], and lately visual similarity techniques [5].
Blacklisting has worked well so far, but the time it takes for a URL to become blacklisted worldwide overlaps in most cases with the time frame in which the phishing attack is most successful. Also, not all of the current content-based solutions make use of whitelists, which can result in the misclassification of sites – for example a filter might treat the official eBay website as a phishing site [6].
In developing our method we started from the following hypothesis: in a given language, the number of different possible ways of phrasing a message that transmits the same or similar information (such as ‘Please log into your online banking account in order to access your funds’) is limited by the writer’s common sense (i.e. the information must be phrased in a simple, readable and understandable form). In other words, we assume that the English login pages of financial institutions will have a large set of common words, since they share a common purpose and specialized financial vocabulary [7], [8], [9], [10], [11], [12].
Two documents, A and B (in our case the web pages of financial institutions such as PayPal or Bank of America), can be represented as sets of words:
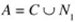
and
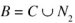
where C represents the common words between the two documents, and N1 and N2 the distinct words. This means that the number of words needed to construct a database with triples of the form (word, document, occurrences), is:
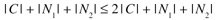
or in short
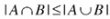
In the case of only two documents, this technique might not be very useful, but in the case of several documents which serve the same purpose (e.g. the websites of financial institutions), we can assume that the outcome will consist of a large number of common words.
We will now define a similarity indicator between two documents, known as the Jaccard distance for sets (A represents the number of elements of set A):

On identical documents, this distance will have a null value, while in the case of similar, but non-identical documents it will be close to 0. Since these are not standard sets (e.g. in ordinary sets, identical elements appear just once, while in this set, we decided that each element – or word – appears as many times as it is found in the document), the distance actually provides an acceptable similarity value, based on the number of words.
On a corpus of 101 financial institutions from three different countries – the top five phished banks in Romania, seven websites from Germany and 89 randomly chosen US institutions which showed a high frequency of email phishing in our internal email corpus, with an average of 100 words per page – we obtained a database of just 4,422 different words, instead of an expected minimum of 10,000 words.
Considering a pool of web pages (such as those described above), we can construct a database in the format presented in Table 1.
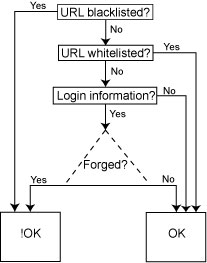
Based on this initial background, our proposed method is outlined in Figure 1. First, the presented web page is verified against a blacklist and a whitelist. Afterwards, some simple heuristics are run on the content of the web page, to check whether it tries to mimic an official login page (e.g. contains a submit button or key words such as eBay, PayPal, etc.). We introduced this step for speed optimization purposes (it would be pointless to check if a web page with no submit form tries to duplicate a web page that has such a form).
If we consider it necessary to run our forgery filter on a target web page, then we start computing the Jaccard distance for each institution on which the filter has trained (the words from learned web pages are stored in the database [only visible words will be stored in the database]). The lowest distance obtained indicates the highest similarity between the target web page and a reference web page in our database. If the computed distance is smaller than a predefined threshold, we consider the target website to be forged.
When dealing with this technology, the use of an up-to-date whitelist is essential in order to prevent the forgery filter being run on original websites, and thus prevent false positives.
Usually, if the filter has been trained on a certain web page, we will have a similarity distance of at least .01, and experimentally (using over 10,000 samples) we never obtained a distance of higher than 0.2 on phishing websites. For training, we used a corpus of 101 pages (presented earlier) and a value of 0.25 for the similarity threshold.
We tested our filter on two different corpuses: one containing 10,000 forged websites of the exact pages on which the filter has trained (randomly selected from real phishing pages) and the other containing the URLs published on PhishTank (http://www.phishtank.com/) over a period of 10 days.
We obtained a 99.8% detection on the first corpus, with 20 false negatives – which were mostly due to the fact that they were generated with screenshots from the original web page and did not show enough text content for a discriminative decision. We obtained a 42.8% detection on the PhishTank URLs. Although this may seem low, our data indicates that we obtained these results due to the fact that 144 hijacked brands were co-opted in phishing attacks in December 2007 (http://www.antiphishing.org/reports/apwg_report_dec_2007.pdf) – which was far more than in our training corpus.
This experiment can easily be reproduced if, in a multicategorical Bayesian filter, we swap the probability function with equation 1 and the probability of each word belonging to a category will represent the number of occurrences of that word in that category. Then, if instead of choosing the category with the highest probability, we chose the category with the smallest distance, we would obtain the same results as presented above.
As for false positives, on a corpus of 25,000 samples of web pages containing login forms, or any other information that would activate the forgery filter, we obtained 10 false alarms. Eight of them were real financial institutions, which would have been in the whitelist if the filter had been properly trained, while the other two were genuine false positives (two online financial newspapers) and this problem can easily be solved by whitelisting the sites.
Right now, because of the lack of content-based solutions [4], [6], phishers are putting only a small amount of effort into customizing their forged websites (e.g. using random invisible content, frames, HTML obfuscation) and concentrating instead on rapidly changing their hosting addresses. Since initially we were expecting a higher rate of false positives, we also developed another distance:

where
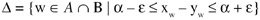
wherein w represents a word, A represents the target word set, B represents the reference word set (A word set represents the list of all words found in the documents. If a word is found 10 times in a certain document, it will also be found 10 times in the word set), xw represents a position index of the word w within the reference word set and yw represents a position index of the word w within the reference word set. We accept a certain number of missing or extra words between different paragraphs if their number is between
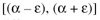
(e.g. we accept a variable but controlled difference between the target and the reference position index).
In equation 2 (which is in fact a modified Jaccard distance), d is close to 0 if the target word set and the reference word set share a large number of words in the same order of appearance, and d is close to 1 if the word sets have few common words and/or the words appear in a different order in the target and reference web pages.
We observed that, although the second distance provides a greater protection against false positives, it will also score more false negatives, since phishers sometimes change the order of phrases when forging a website.
Since phishing websites are no longer solely advertised through email, we believe that it is time for companies to invest more in the research and development of browser-level anti-phishing protection.
The proposed method is intended to be used alongside current technologies, providing the user with extra information about visited web pages. Although not a complete solution on its own (it is ineffective on phishing websites that do not mimic the original website), when used in combination with other technologies (e.g. blacklists, content and URL heuristics) it increases the value of any anti-phishing toolbar.
The obtained results show that this is a viable method to provide forgery detection for the websites of legitimate financial institutions. It is not necessary to run this system on all the pages visited by the user, focusing just on those that require the user to submit information, thereby highly increasing the user’s tolerance level by decreasing the time required for analysis.
This work was supported by BitDefender AntiSpam Laboratory. The author thanks Mr Lucian Lupsescu and Mr Razvan Visan for their help in developing this project.
[2] Hatlestad, L. McAfee’s Avert Labs is warning of a new threat from hackers: phishing via SMS. VARBusiness 31 August 2006.
[3] Jagatic, T.; Johnson, N.; Jakobsson, M.; Menczer, F. Social Phishing. School of Informatics, Indiana University. 12 December 2005.
[4] Cranor, L.; Egelman, S.; Hong, J.; Zhang, Y. Phinding Phish: An Evaluation of Anti-Phishing Toolbars. 13 November 2006. CMU-CyLab-06-018.
[5] Wenyin, L.; Huang, G.; Xiaoyue, L.; Min, Z.; Deng, X. Detection of phishing webpages based on visual similarity. WWW 2005. ACM 1-59593-051-5/05/0005.
[6] Wu, M.; Miller, R. C.; Garfinkel, S. L. Do Security Toolbars Actually Prevent Phishing Attacks? CHI 2006.
[7] Landauer, T. K.; Foltz, P. W.; Laham, D. An introduction to Latent Semantic Indexing. Discourse Processes 25, pp.259–284.
[8] Kelleher D. Spam Filtering Using Contextual Network Graphs. 2004. https://www.cs.tcd.ie/courses/csll/dkellehe0304.pdf.
[9] Shin, S.; Choi K. Automatic Word Sense Clustering Using Collocation for Sense Adaptation, 2004. KORTERM, KAIST 373–1.
[10] McConnell-Ginet, S. Comparative Constructions in English: A Syntactic and Semantic Analysis. 1973. University of Rochester.
[11] Merlo, P.; Henderson, J.; Schneider, G.; Wehrli E. Learning Document Similarity Using Natural Language Processing. 2003. Geneva.
[12] Biemann, C.; Quasthoff, U. Similarity of documents and document collections using attributes with low noise. 2007. Institute of Computer Science, University of Leipzig.
[13] Ceglowski, M.; Coburn, A.; Cuadrado, J. Semantic Search of Unstructured Data Using Contextual Network Graphs. 2003.
[14] Prakash, V.; Abad, C.; de Guerre, J. Cloudmark’s unique approach to phishing. 2006. Extracted from: http://www.antiphishing.org/sponsors_technical_papers/cloudmark_unique_approach.pdf.
[15] Dhamija, R.; Tygar, J. D.; Hearst, M. Why Phishing works. Proceedings of the SIGCHI conference on Human Factors in computing systems. 2006.
[16] Dhamija, R.; Tygar, J. D. The battle against phishing: Dynamic Security Skins. Proceedings of the 2005 Symposium on Usable Privacy and Security.
[17] Tally, G.; Thomas, R.; Vleck, T. V. AntiPhishing: Best Practices for Institutions and Consumers. McAfee Research, Technical Report – AntiPhishing Working Group white paper. 2004.
[18] Yee, K.-P. Designing and Evaluating a Petname Anti-Phishing Tool. 2006. University of California, Berkeley.
[19] Hall, K. Vulnerability of First-Generation Digital Certificates and Potential for Phishing Attacks and Consumer Fraud. 2005. GeoTrust white paper.
[20] Li, L.; Helenius M. Usability evaluation of antiphishing toolbars. Journal in Computer Virology, Eicar 2007 Best Academic Papers.
[22] Wu, M.; Miller, R. C.; Little, G. Web Wallet: Preventing Phishing Attacks by Revealing User Intentions. Symposium on Usable Privacy and Security 2006.