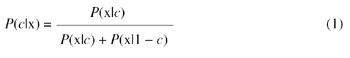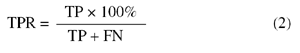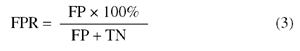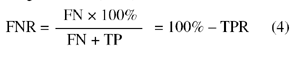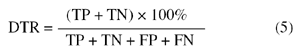2008-08-01
Abstract
Heuristic detection can provide valuable assistance to help security analysts in achieving zero-day malware detection. Newaz Rafiq and Yida Mao discuss a novel heuristic detection technique with a high level of accuracy and a high level of adaptability to meet the challenge of new malware.
Copyright © 2008 Virus Bulletin
With proven accuracy, predictability, performance and scalability, heuristic detection can provide valuable assistance to help security analysts in achieving zero-day malware detection. In this article we will discuss a novel heuristic detection technique with two major advantages:
A consistently high level of accuracy in malware prediction.
A high level of adaptability to meet the challenge of new malware.
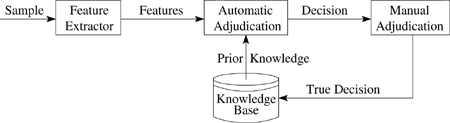
Our approach starts with a model that resembles the behaviour of our security analysts.
To make a prediction about a sample we need to extract features from it, just as security analysts collect features from the sample executables. Analysts have prior knowledge of malware features. They know which features characterize malicious behaviour and which indicate non-malicious files. They decide whether a sample is malicious or not based on their prior knowledge of its features. But some of the features will be new to the analysts, in which case they upgrade their prior knowledge by adding details of the new features. Our system works in exactly the same way. Figure1 shows the model on which our automatic file classification system is based. As an automated heuristic approach alone cannot be relied on to give 100% accurate detection, a manual check is incorporated before committing any new features to a knowledge base.
Features can be extracted from the static and run-time behaviours of malware samples. We are able to extract hundreds of features from each executable; some of the most notable ones are described here:
File size has been shown to be an important feature both in our investigations and in other studies [1]. In our initial experiments we divided executables into three groups based on their file size:
Group 1: executables whose file size was smaller than 1 MB.
Group 2: executables whose file size was smaller than 5 MB and greater than or equal to 1 MB.
Group 3: executables whose file size was greater than or equal to 5 MB.
After normalizing the counts in each group, we arrived at the results shown in Table 1.
According to Table 1, samples contained in groups 1 and 2 have an approximately equal chance of being malicious or non-malicious, thus the file size does not reveal any useful information for malware detection. However, executables belonging to group 3 (file size > 5 MB) are significantly more likely to be non-malicious than malicious.
In our investigations we divided the executables into two groups: obfuscated and non-obfuscated. Obfuscation can be achieved by packing the full sample or a portion of the sample binary, by reordering instructions, and so on. We found that approximately 60% of recent malware is obfuscated. We determined that if an executable is obfuscated, there is a greater than 95% probability that it is malware.
An executable consists of sections, such as header, text, code and so on. There are generally fewer sections in malicious files than in non-malicious ones. In our analysis, more than 70% of the malware samples consisted of two or three sections, while more than 70% of non-malicious files consisted of four or five sections. In further analysis focusing on section names, we found that over 80% of malicious programs used unconventional section names, whereas only 3% of non-malicious programs used unconventional names. We also found that some executables used duplicate section names, although this was very rare (only 4%). If there is a duplicate section name, then there is a more than 95% probability that the executable is malware.
We found that use of the resource section (.rsrc) was a good indicator of a sample being malicious (with more than 70% probability), the presence of read-only data (.rdata) meant that the sample had a greater than 70% chance of being non-malicious, and the presence of import data (.idata) was also a good indicator of the sample being non-malicious (with more than 80% probability).
Another notable feature relates to peculiarities in the executable structure – for example, some sections in the executable may not be aligned properly. In our analysis, more than 78% of malware revealed an anomaly in the executable structure, while only 5% of non-malicious samples had an anomaly in their structure. If an anomaly exists, there is a more than 93% chance that the sample is malicious.
Browser Helper Objects (BHOs) are program modules (DLLs) designed as plug-ins to provide added functionality for Microsoft’s Internet Explorer web browser [2]. BHOs have access to all the events and properties of a web-browsing session [3]. This means they give developers almost complete control over Internet Explorer functionality. For malware writers this is a compelling reason to use BHOs.
According to our analysis, if an executable uses a BHO, it can likely be classified as malware with 98% probability.
Services are employed to enable long-running executable applications to run in their own Windows session [4]. These services can be started automatically when the computer boots, can be paused and restarted, and do not require a user interface. Services start when the Windows operating system is booted and they run constantly in the background as long as Windows is running. Services can run for a specific user account that is different from the logged-on user or the default computer account.
According to our analysis, if an executable runs as a service, it can likely be classified as malware with 98% probability.
As part of our investigations we also calculated statistics relating to the importing of DLL files. For example, if an executable imports system32.dll, then the sample has a more than 77% chance of being malware and if it imports kernel32.dll, then the sample has a more than 67% chance of being malware.
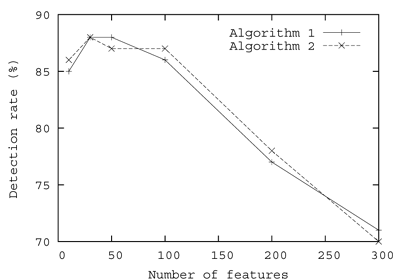
The accuracy of malware detection depends heavily on the selected features on which predictions are made [5]. Figure 2 shows our experimental results using two different feature selection algorithms.
From Figure 2 we can conclude:
An increase in the number of features does not guarantee better detection.
A feature selection algorithm should be chosen carefully.
To understand how feature selection helps in the malware detection process, assume that we have 500 items, of which half are malicious and half are non-malicious. These will be used to train our system. Also assume that we have detected three features: A, B, and C, for each of the 500 samples.
From our statistical analysis, we obtain the information content of each feature, as shown in Table 2.
In our model, we assign samples a ‘likelihood’ score. The closer the likelihood score is to one the more likely it is to be malware, and the closer the score is to zero the more likely it is non-malicious.
Now assume that an executable X has two features: A and C. The likelihood scores for X according to the features selected are given in Table 3.
Table 2 indicates that more information can be drawn from feature C than from feature A. This is also reflected in Table 3. If the feature selection algorithm selects A, then the likelihood score for X is 0.49, which is inconclusive. A similar score is achieved when two features, A and C, are selected for the adjudication process. But if feature C alone is selected the likelihood score is 0.88, which tells us that X is malware.
| Feature | A | B | C | A,C |
| Likelihood score | 0.49 | 0.10 | 0.88 | 0.43 |
Table 3. Likelihood scores for X according to selected features.
For this reason, feature selection is very important for malware detection. We have devised a few simple and time-efficient techniques to select the most informative features that produce a high accuracy of malware predictability. Some of these have been published in our previous work [6].
There are many classification algorithms at our disposal. Currently we are using the naive-Bayes classification algorithm as it is both accurate and simple to implement. The simplified algorithm (assuming that there are only two classes: malware and non-malware) is given in Equation (1).
Where x = [x1, x2, · · · , xn] is an array of selected features from an executable, P(c|x) is the a posteriori probability that the executable with feature set x is in class c, and P(x|c) is the probability of x occurring in class c.
To evaluate our system, we use the following quantities:
True positive (TP): the number of malicious files classified as malware.
True negative (TN): the number of non-malicious files classified as non-malware.
False positive (FP): the number of non-malicious files classified as malware.
False negative (FN): the number of malicious files classified as non-malware.
True positive rate (TPR):
False positive rate (FPR):
False negative rate (FNR):
Detection rate (DTR):
K-fold cross validation is one way to determine the characteristics of an algorithm. In this technique, the data set is divided into k subsets. One of the k subsets is used as the test set and the other k -1 subsets are merged together to form a training set. The advantage of this technique is that each sample contributes to the system performance.
We fine-tuned several parameters using the cross-validation technique, but we describe only one of them here: number of features.
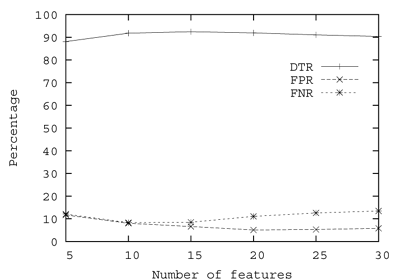
To begin, we used around 7,000 known executables (54% of which were malware) to train our system and to fine-tune the initial system parameters. We varied the number of features from five to 30 and plotted the results as shown in Figure 3.
As can be seen in Figure 3, our detection algorithm produces the best DTR when the number of features is 15, the best FPR when the number of features is 20, and the best FNR when the number of features is 10. For this reason, we experimented with our algorithm using newly detected malware samples when the number of features was 15. The results are described in the following section.
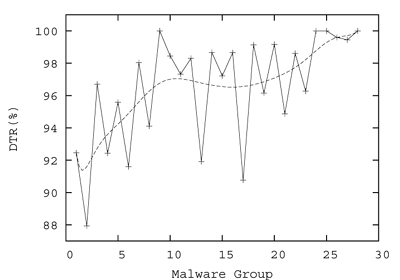
We used one group of non-malware and 28 released malware groups that had been detected by our analysis team in recent months. Each group contained around 150 to 300 samples. We plotted the results of our experiment in Figure 4. A smooth, dashed curve shows the recognition pattern. In almost all cases, the malware recognition rate is above 90%. As the automatic decision-making system is trained using more malware samples, the system utilizes more features and accuracy continues to rise to 100%. Our system is currently recognizing non-malware with more than 90% accuracy.
To gain an understanding of why our system is not 100% accurate, we have referenced the features of two malicious and two non-malicious samples in this section. We consider only those notable features that were described earlier. The features shown in bold are malware-characterizing features and the rest are non-malware-characterizing features.
Malware sample 1: number of sections = 2, no resource usage.
Malware sample 2: kernel32.dll, anomaly, no. of sections = 5, import data.
Non-malware sample 1: kernel32.dll, user32.dll, anomaly, no. of sections = 5, read-only data.
Non-malware sample 2: kernel32.dll, unconventional name, anomaly, obfuscation, import data, read-only data.
From the above information we can conclude that each malware sample has some malware-characterizing features. However, non-malware-characterizing features overpower the effect of malware-characterizing features. The same is true for non-malware. This means we are very unlikely to achieve 100% detection. However, by using diverse features and a more interesting feature selection algorithm we can attempt to achieve a close to perfect detection rate.
The main features of our automatic file classification technique are as follows:
The ability to extract hundreds of features.
An intelligent feature selection algorithm.
The ability to fine-tune system parameters.
The option to update the knowledge base easily.
We are consistently getting more than 90% accuracy detection of malware. The FPR of our system is around 10% and we are trying to reduce this by extracting new features and by developing a new feature selection algorithm.
[1] Lu, B. A deeper look at malware – the whole story. Proceedings of the 17th Virus Bulletin International Conference, 2007, pp.9–17.
[4] Introduction to Windows service applications. http://msdn2.microsoft.com/en-us/library/d56de412(VS.80).aspx.