2008-07-01
Abstract
Adware programs have variously been dressed up as providing anti-phishing protection, intrusion detection capabilities as well as the ‘benefit’ of targeted advertising, but their presence is still a considerable nuisance to many. Here, Lysa Myers looks into the dubious world of Internet advertising and looks at the effects of programs such as AntiPhorm on adware in general.
Copyright © 2008 Virus Bulletin
Advertising has become an integral part of everyday life – it is almost completely unavoidable. Movies and TV shows have even depicted a fantasy future world in which advertisements appear in our dreams, and on ‘smart billboards’ which track our every move. Recent developments in targeted advertising have brought the latter scenario increasingly close to a present-day possibility [1], but there are many who find this a completely nightmarish prospect.
In order to obtain this sort of targeted information, advertisers are looking to dig ever deeper into our lives. This naturally raises privacy concerns for those who would prefer not to allow such personal information to get into the hands of complete strangers.
Advertising on the Internet has been a technological testing ground for new information-gathering techniques, and for pushing the boundaries of what is considered acceptable information-gathering behaviour. Almost every sort of network traffic has been used to send advertising content, and now more and more traffic is being monitored in order to tailor such content.
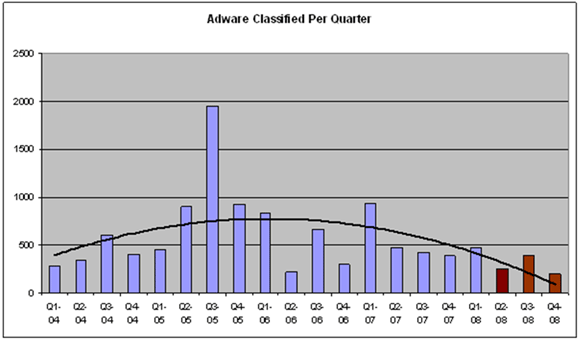
What if there was an effective way to dissuade advertisers from using such invasive techniques? The rise of anti-spyware programs that detect invasive adware as ‘potentially unwanted programs’ (PUPs) has arguably had some effect on the declining prevalence of advertising software placed on users’ computers (see Figure 1). But what can be done when the invasion is being generated from somewhere other than the users’ machines?
The Internet originally started as a place for people to share information and services freely. In order to fund the time and resources needed to maintain a popular website, people needed to come up with ways to make money from the services/information they were providing. Some made their sites subscription-based, charging a fee for their services. Most of the rest turned to advertising revenue as a source of income.
As more sites have turned to using advertising to fund themselves, many are looking to maximize profitability for the advertisers and increase the relevance of advertisements to the user. Demographic information, web-search and email content, as well as Internet surfing habits have all been used to customize advertising content. Demographic information is generally gathered by compulsory registration, whereas surfing habits and email/web-search content is typically gathered without any user interaction.
Many users are offended by what they perceive to be an invasion of their privacy, being obliged to provide personal (even if not personally identifiable) information to an advertiser. Some of these people tried to decrease the incentive for advertisers to gather information this way by providing them with fake information.
BugMeNot was a weekend project that was started in August 2003 by an Australian named Guy King [2]. At that point one of the more popular ways for websites to obtain targeted demographic information for advertisers was to require visitors to complete a free registration before allowing them to access content on their sites. This way they could get information about a user’s zip code, salary range, gender, date of birth or specific interests, and then sell that information to advertisers.
King created a massive database of information with which to complete the registrations for sites that used this technique, asking the users of BugMeNot to help populate this database. A number of rules were put in place to keep people from using it for fraud, or other malicious activities.
Part of the success of BugMeNot could be attributed to the developer’s decision to make the database accessible via a plugin for Firefox – the timing was such that Firefox was just becoming popular, and many technology and productivity blogs cited the BugMeNot plugin as a compelling reason to switch from Internet Explorer. Coupling the open-source spirit of the BugMeNot database with the Firefox browser was a natural match.
In the years since BugMeNot became popular, many websites have abandoned compulsory registration. By poisoning the websites’ user databases with bogus details on such a wide scale, the information that sites gathered was rendered useless for the purposes of selling to advertisers. The information could not be considered sufficiently trustworthy to ensure advertisers were targeting ads to the right demographic.
BugMeNot was a simple solution for a simple problem, and its story is relatively straightforward. The next generation of data-mining for advertising would be far more intrusive and complex, and its story full of twists and turns.
In 2000, some years before compulsory registration reached its highest point, Google began selling ads based on search keywords. As these were text-based and visually unobtrusive, the ads were generally considered less offensive than the banner ads which were most common at the time. The privacy concerns were few, because search terms were not considered personally identifiable information and because the data that was captured was not intended to leave Google.
For those who objected to these keyword ads, two Firefox plugins were created, TrackMeNot and SquiggleSR. These were both designed to create fake searches, to lose the genuine keyword content amongst a flood of automatically generated searches. The traffic from these applications has never been sufficient to motivate any behaviour changes on the part of the search engines.
In April 2004 Google introduced Gmail, a free web-mail service which boasted 100 times the storage capacity of its leading competitors at the time. To support this service, Google included advertising alongside each email viewed, in a form similar to that of the text-based ads that were used in the company’s search service. The ads were generated by parsing the content of the email, to ensure relevant content.
This was considered by many to be a serious violation of privacy, as email is ostensibly a private conversation between the sender and the intended recipient(s). Since there were many competitors in the web-mail market, people who found this practice unacceptable generally simply chose an alternative provider.
In the end, Gmail was considered a resounding success, and the advertising was viewed by the majority of its users as an acceptable cost for this free service. This success seemed to embolden other advertisers, who saw that users would accept their content being filtered to allow more relevant ad content. However, there were two lessons that these advertisers didn’t seem to learn from the success of Gmail or the failure of compulsory registration. One was that in order for this to be acceptable, the user had to be given something of significant monetary value. The other was that allowing your advertising database to be accessed by outside parties was considered a greater privacy violation.
In July 2007 British Telecom (BT) began a test with a company called Phorm who used deep packet inspection at the ISP level to gather information on the web-surfing habits of its subscribers and subsequently deliver tailored advertising content. Phorm has claimed that it scrubs the content it stores of any personally identifiable information, and that it can also act as an anti-phishing measure as it keeps a list of known phishing sites to prevent users from accessing them.
However, the test was performed in secret, without the knowledge or consent of BT’s user-base. It wasn’t even widely known that the testing had occurred until the beginning of 2008. This did not set the experiment off on a good note. If this was something that would benefit the user, would the company not have advertised this fact?
Phorm had previously been known by another name (121media). In its previous incarnation the company had been associated with an adware application called Apropos, which used some of the most devious and sneaky tactics of any such program. The company closed its doors in 2006.
At about the same time as Phorm came on the scene, a number of other similar entities began to partner with other ISPs to perform similar data-mining activities. The most well known of these are NebuAd, Front Porch, Adzilla and Project Rialto.
The most similar to Phorm is NebuAd, which has partnered with a number of US-based ISPs, most notably Charter Communications. Adzilla, like NebuAd and Phorm, also confines itself strictly to the collection of ‘anonymous’ web-surfing traffic. It also sells its database to outside parties, in order to serve targeted ad content. Unlike NebuAd and Phorm, there is little mention anywhere of which ISPs Adzilla is partnered with.
Front Porch promotes itself in a significantly different tone. Whereas Phorm, NebuAd and Adzilla all stress the importance of increasing the relevance of ads, Front Porch flaunts the ability it gives ISPs to modify their users’ Internet experience. It gives the following list of popular uses:
Redirect subscribers to your portal or a partner’s site, regardless of their browser home page settings.
Offer limited web access to specified subscribers, enabling full access once your conditions are met.
Redirect subscribers to a partner search engine when they conduct online searches.
Create a ‘walled-garden’ of allowed sites for specific subscribers.
Project Rialto has also taken a rather different approach. It is now known as Kindsight, and its stated purpose is to provide intrusion detection with its traffic monitoring. The company states that this service is ‘funded through an advertising mechanism’, providing the users with ‘ads on sites that are of interest to the subscriber base’.
Since the deep packet inspection of companies like Phorm was coming from the ISP, and in many areas there are few, if any, competitors for broadband access, a software solution was sought. AntiPhorm is a stand-alone program which generates fake web-surfing traffic, intended to bury a user’s genuine web-surfing behaviour in a flood of automatically generated traffic. While it was created specifically to work against Phorm, it also works with other surfing-trackers and adware applications.
Web surfing is a rather risky business today, with malware infecting legitimate sites as well as more seedy ones. The AntiPhorm developers were conscious of this and have taken a variety of steps to minimize any risk to the user caused by additional surfing.
In hidden and text-only modes AntiPhorm pre-filters the content it receives to exclude JavaScript, images, video and Flash. It doesn’t execute HTML code directly in the browser when in console or hidden mode. Lists of keywords and URLs are both completely customizable, so a user can further restrict what traffic is allowed.
The purpose of AntiPhorm is to create extraneous and erroneous entries in the advertisers’ database, reasonably safely. It seems well suited to this purpose. But will it be as effective as BugMeNot in curbing the greater adware trend? While AntiPhorm doesn’t currently have the benefit of riding the rising popularity of an Internet browser, there are a few outside factors which could work in its favour.
The first is the growing awareness that even information which does not appear to be personally identifiable can be, when taken in context. When a text file containing search keywords from AOL was accidentally released on the Internet, it quickly became apparent that information from searching could easily be used to identify the searcher [3]. By ego-surfing, entering addresses or social security numbers, a user’s search could easily be mapped to their ‘anonymous’ numeric ID.
There is also a growing sentiment that the BT/Phorm tests were illegal, and that the only legally acceptable option is for Phorm to be used as an opt-in service rather than opt-out as it is currently set up by most ISPs [4]. This sentiment has been detrimental to Phorm in signing up new partners – both MySpace and The Guardian declined to partner with the company in light of the negative public sentiment [5].
While adware applications have been on the decline recently, their presence is still a considerable nuisance to many. As AntiPhorm is a free utility, it may gain popularity with a wider audience who seek to thwart adware thrust upon them by certain freeware vendors [6].
On the other hand, there is one thing that may severely hinder the effectiveness of AntiPhorm. Where compulsory registration was used on some of the most popular websites on the Internet, deep packet inspection is used by only a small handful of ISPs at the time of writing. As negative publicity increases for this sort of monitoring, more ISPs are making it opt-in rather than opt-out. It’s unlikely to continue to increase in popularity, and it may not ever rise to be the level of nuisance posed by adware.
In effect, the biggest threat to the usefulness of AntiPhorm’s advertising database poisoning may simply be that Phorm may never gain sufficient popularity. Phorm may collapse under the weight of its own bad PR. Perhaps AntiPhorm would be best advised to re-brand to appeal to a wider audience of Internet users who are tired of all content monitoring, regardless of the commercial entity behind it.