2008-01-01
Abstract
Over the last few years anti-virus researchers have faced an increasing volume of malware samples arriving at their research labs on a daily basis. Víctor Álvarez presents a simple, rule-driven approach to malware identification and classification that complements the manual work of the malware researcher by compensating for the weaknesses of the human brain.
Copyright © 2008 Virus Bulletin
Over the last few years anti-virus researchers have faced an increasing volume of malware samples arriving at their research labs on a daily basis. But it is not only the number of samples that has been growing; malware diversity is increasing as well. Gone are the days when a virus researcher could recognize all existing malware families unassisted.
A fully automated classification system capable of identifying malware families without human intervention would be great. Indeed, a lot of researchers are already working on building such systems, but it is a complex task and they still have a long road ahead. In this article we will discuss a simpler, but effective, approach. Rather than trying to remove the need for human interaction altogether, our approach complements the work of the malware researcher by providing tools to cope with weaknesses of the human brain.
I have witnessed first hand the way in which researchers tackle the challenge of recognizing malware families by taking a quick glance at a hex dump or disassembly listing. If you are a malware researcher too, you will know what I mean. If not, then follow me in a little experiment.
Take a look at the string below for a few seconds, then look away from the screen, and try to write it down from memory:
5B 3A 78 0E 21 05 90 90 4F 34 C1 B4
It’s not easy, is it?
The following string should be a lot easier to remember:
Hello, I’m a plain text
In general, humans are not good at remembering numbers, especially long sequences of them – this is one of our limitations. Researchers tend to recognize malware families by remembering textual information contained in executable files. Windows registry entries, file names, URLs, messages from the malware author, and any kind of legible text are good candidates to be remembered.
However, the human brain is not a hard drive where information persists until you delete it. We forget things involuntarily, especially irrelevant things like, say, those text strings contained in the Spamta worm seen last month. It is a frequent occurrence for a malware researcher to look at a file, recognize some strings, and just as if it were somebody’s face, say to himself: ‘I know I’ve seen this piece of malware before ... but I can’t remember its name!’ So here is our second limitation: the human memory is not reliable.
Our third limitation concerns knowledge sharing, or lack thereof. Even when working in a highly cooperative team, malware researchers accumulate a lot of experience on an individual basis, which is hard to transfer from one to another. They cannot meet at the end of the day and explain to their co-workers every small detail they have learned during the day. The malware classification knowledge of the team as a whole is fragmented and scattered among team members, and this knowledge is frequently lost and regained as people come and go.
On the other hand, humans perform extremely well when it comes to extracting distinctive information from malware samples and deciding which are the common characteristics shared by different variants of the same family. For a computer this can be a difficult task, but a human being can take a look at some samples of, for example, the Gaobot worm family and almost immediately conclude: ‘Ah ... all of them seem to contain some of the strings: “lsass”, “dcom”, “webdav”, “bagle” and “mssql”; and all share the strings “HELO” and “SMTP” as well.’ Humans can deduce even more complex generalizations with relative ease.
By translating the knowledge accumulated by malware researchers into a set of computer-understandable rules, and storing them in a centralized database, the limitations of our poor memory and lack of information exchange among team members can easily be solved. Let us return to our Gaobot example, and imagine we have some way of instructing a computer program that when a file appears with at least one of the strings: ‘lsass’, ‘dcom’, ‘webdav’, ‘bagle’ or ‘mysql’, and also contains the strings ‘HELO’ and ‘SMTP’, it is likely to be a Gaobot’.
With such a rule stored in a database, and a program capable of understanding the rule and verifying whether a given file satisfies it or not, we no longer need to remember it – and any time a new rule is added to the database, it is immediately accessible by the rest of the team, allowing everybody to enjoy the benefits. Furthermore, while the strings of our example are all plain text, we don’t have to limit ourselves to text strings in the rules. As all the information will be stored in a database and not in our brain, binary strings can be used in the rules as well – it’s all the same for computers after all.
Of course, we need a more formal way to express these rules that both computers and humans can understand. So let’s define a rule as a set of binary or text strings related by some logical expression written in a computer-understandable language. For example:
Description:
‘Bad file’
Strings:
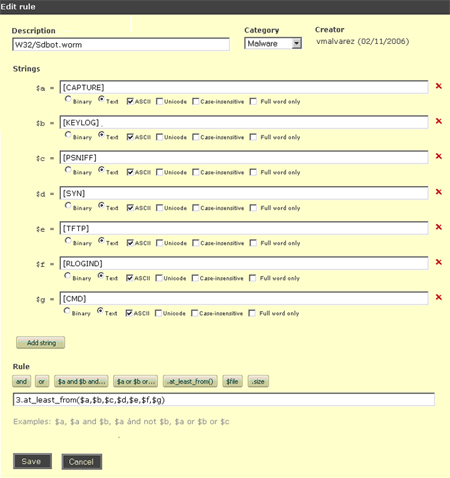
$a = ‘foo’
$b = ‘bar’
$c = {0x12,0x34,0x56,0x78,0x9A}
Expression:
($a or $b) and not $cThis rule states that any file containing the text strings ‘foo’ or ‘bar’, and not containing the hex string 0x12 0x34 0x56 0x78 0x9A is a ‘bad file’. The variables $a, $b and $c should evaluate to true or false, depending on the presence or absence of the corresponding string in the file, and the boolean value of the whole expression determines whether the file satisfies the rule or not.
By creating appropriate rules for each malware family, researchers can store the characteristics they have found belonging to those families in a persistent and easy-to-share repository. Of course this implies an additional task for them: creating and testing the rules. But in the long run it will facilitate their work, and help to reduce the inconsistencies in malware naming produced when each researcher applies his own criteria to malware classification without any kind of information exchange with the rest of the team.
When we started the development of a malware classification system based on logical rules and strings at PandaLabs we had a clear idea of what we wanted, but we didn’t know which exactly was the best way to go about it.
One of the requirements of the system was that the rules describing malware families should be stored in a central repository accessible to any of our researchers at any time. Each researcher should be able to create, browse and modify rules quickly and easily, so we decided to store them in a relational database accessible through a web interface. However, researchers also need a tool to scan a given file and check whether it satisfies any of the rules in the database whenever they want. Such a tool needs to perform a lot of queries against the database in order to accomplish its task, and we quickly realized that if we kept the information completely centralized this would lead irremediably to bad performance issues, due to the high volume of network traffic.
So we decided to adopt a semi-centralized solution. In our system the information is stored in a central database, which can be modified through a web interface as mentioned above, but the program responsible for scanning files doesn’t query the database directly. Instead, it uses a special file containing a replica of the information stored in the database, which can be generated on demand any time we want to have a fresh copy of the data. This file is just like the signature files of anti-virus programs, which are local copies of virus signatures that anti-virus companies store in relational databases centrally. From now on in this article, whenever we mention the database we will be referring to this file.
The algorithm for deciding which rules a given file satisfies and which it does not, starts by scanning the file to determine whether it contains any of the strings in the database. The scan is performed in a single pass, and the program takes note of all the strings that are found. Later, the logical expression of the rules associated with the found strings are evaluated, and if some of them are true, the appropriate information about the matching rule is reported to the user.
We should address an important issue before continuing the description of the algorithm. When we talk about scanning a file to determine the strings it contains, we assume that we have a non-packed file or an unpacked version of the file to scan. The use of packers to hide the content of executable files and make their reverse engineering harder is a common practice among malware authors, however anti-virus labs already have the appropriate tools to cope with this problem (which are outside the scope of this paper). We assume that unpacking, if necessary, has already been undertaken as a previous step before the application of this classification technique. Now, let’s continue with the explanation of the scanning algorithm.
The file is scanned by moving a cursor over the data one byte at a time. On each iteration two bytes are read from the cursor position, let’s call them X and Y, and the database is searched for strings which start with XY. The search is performed by using X and Y as coordinates on a 256 x 256 matrix stored in the database.
At position (X,Y) of the matrix there is a pointer to a list containing all the strings on the database whose first two bytes are X and Y. The cell (X,Y) will be empty if there are no strings starting with XY. What we are doing here is just hashing the strings of the database by using the first two bytes as the hash key. This way the whole set of strings is split into more manageable subsets to improve performance. Finally, if the cell (X,Y) is not empty, the list will be searched for strings matching the file content at the cursor position. To improve the performance a bit more, the strings in the list are sorted, allowing us to perform binary searches instead of exhaustive ones.
Once the strings contained in the file have been found, it’s time to evaluate the associated logical expressions. At first we thought about developing our own parser and evaluator, but later decided to take a short cut. While playing around with Python’s interactive interpreter, the idea of writing the expressions in some interpreted language, which could be embedded into our C application, came to mind. There is certainly no need to reinvent the wheel, and the power of such languages could be very useful to expand the expressiveness of the expressions in the future.
Python and Ruby were our two candidates, both of which fulfil the requirements, but we finally decided on Ruby because there is a wonderful framework for web development named Ruby on Rails, which is based on this language, and we thought it would be nice to use it in the system’s web interface. Remember that rules are managed through that web interface, and it is necessary to perform some syntax check on the expressions before updating the database. If the expressions are written in the same language as that used to develop the server side of the web interface, the task is simplified significantly.
Using the Ruby interpreter to evaluate rule expressions proved to be a good decision, because it allowed us to expand the features of our system without major effort. We quickly realized that a rule based only on the presence or absence of some strings in the file is not always sufficient. Sometimes we need to include in the rule some other aspects of the file to fine-tune it and make it more precise. For example, it would be nice to guarantee that certain rules are satisfied only by Portable Executable (PE) files, or maybe by dynamic link libraries, or we may want to ensure that the file size is within a certain range.
To allow this kind of additional check we introduced the special variable $file. This variable doesn’t hold a boolean value like $a, $b, $c, and so on, because it doesn’t indicate the presence or absence of a given string. The $file variable holds an object that represents the file being analysed, and exports some methods and properties that can be used in rule expressions. For example, $file.is_pe returns true if the file is a PE, and $file.is_dll returns true if it is a DLL. Also, we can get the file size by using $file.size, and expressions such as $file.size < 1000 can be used to ensure the file size doesn’t exceed 1,000 bytes.
Furthermore, as Ruby is a fully object-oriented language, where even a numerical constant like ‘64’ is an object of the built-in class Integer, and where built-in classes can be extended by providing new methods for them, we added the methods KB and MB to the Integer class to allow expressions like this:
$file.size > 64.KB and $file.size < 1.MB
Function calls are also allowed in rule expressions. For example, we implemented the offset() function, which receives one of the string variables ($a, $b, $c,...) and returns the offset of the first occurrence of that string in the file. If $a = ‘MZ’, the expression offset($a) == 0 will be true for any file containing the string ‘MZ’ at the very beginning, as any DOS or Windows executable file will do. A similar function called rva() returns the relative virtual address of the string if the file is a PE file. The expression rva($a) == $file.entry_point_rva will be true for PE files containing string $a at their entry point. In this case $a should be a hex string, because looking for text strings at executable entry points doesn’t make sense at all.
Another interesting function is rule(), which is used to obtain the result returned by another rule when applied to the same file. Each rule in the database has a unique numerical identifier that rule() expects as input, returning true or false depending on whether the file satisfies the rule or not. Using this function we can make rules more modular. For example, we can create a rule for detecting executable files containing their own SMTP engine. This can be done by searching for strings used in the SMTP protocol (‘HELO’, ‘EHLO’, ‘MAIL FROM’, ‘RCPT TO’, etc.).
If we want to create a rule for identifying a particular Internet worm family which is known for implementing its own SMTP engine, we can write an expression like $a and $b and rule(345), supposing that $a and $b are distinctive strings for the particular family we want to identify, and 345 is the identifier of the rule for detecting SMTP engines. In this way we don’t need to repeat ourselves whenever we want to write rules for SMTP-aware worms, and the SMTP rule by itself can be useful to alert us about executable files containing their own SMTP engines – since this is not a very common characteristic on normal applications.
This rule-driven classification and identification system has proven to be a useful tool for our malware researchers at PandaLabs. However, it should be noted that its power also constitutes its weakness. Because the strings are searched all over the target files, they must be chosen carefully when creating new rules to avoid false positives or misidentification.
A great background knowledge of malware analysis is required in order to create really effective and trustworthy rules. On the other hand, the system can be used not only to identify malware families, but also to identify the compiler used to build executables; to determine if a file was generated with installation software like InstallShield, NSIS, and similar tools; and to locate shellcodes and IP packets commonly encountered in Internet worms. I’m sure there are other uses for the system that we have not yet discovered.