Posted by Martijn Grooten on Mar 10, 2017
Unexpected though it may have been, the SHA-1 collision found by researchers at CWI Amsterdam and Google earlier this year is one of the biggest security stories of 2017 thus far.
Now, stories about breaking cryptographic protocols tend to attract a disproportionate amount of media attention compared to the likelihood of them ever being exploited in the wild. This is also the case for the SHA-1 collision, but at the same time, it is important to understand that the chance of an in-the-wild exploit isn't zero.
To see what an adversary could possibly do, it is good to understand a little bit about how SHA-1 works.
In a significantly simplified version of the algorithm, sufficient for a basic understanding, a byte string whose SHA-1 is to be computed is split into a number of blocks of the same fixed length (the fact that the need for padding is ignored as one of many simplifications). A compression function is then used on the first block, the output of which is mixed with the second block. The same compression function is applied to this new outcome, which again is mixed with the next block, and so on, until the final block is mixed in and the compression function is applied again. The output of this last compression is the SHA-1 hash of the byte string.
An important property of this technique, which SHA-1 shares with its predecessor MD5, is that if two byte strings have the same SHA-1 hash (in other words, they form an SHA-1 collision), then extending both strings with one or more blocks that are the same, will once again result in colliding strings.
The two PDFs created as part of the 'Shattered' attack consist of three parts each. The first part is a simple PDF header, which is the same for both files. Then there is a second part, which contains the actual collision and which is different in the two files. These two parts together collide, so the third part, which is again the same in both files and turns the two byte strings into working PDF files, results in two colliding byte strings – in this case, colliding PDF files.

Anyone could simply take the first two parts of the two PDFs and finish them in a different way to create two more colliding documents. At a first glance, this isn't particularly interesting. If the first PDF says: "the signer of this document promises to pay me 1,000 dollars", then so does the second PDF, while one could make someone digitally sign one of the PDFs (using a signature algorithm that involves taking the SHA-1), and then claim they signed the other one, this isn't particularly meaningful. No one unknowingly signed away 1,000 dollars.
Some people, however, are cleverer than that. One such person is Andrew R. Whalley, a security researcher at Google, who used the collision to create colliding HTML files:
The sha1 collision blocks might have been a PDF header, but now we have them... https://t.co/v2vJRohBR0 https://t.co/FxdtQyJNyK pic.twitter.com/1zdD3Z8UXs
— Andrew R. Whalley (@arw) February 23, 2017
Whalley used the very same collision technique as the original researchers, starting with the PDF (!) header and the same collision blocks as in the original collision, and then finished them off with HTML code that was the same for both pages.
The resulting HTML files contain anything but valid HTML: they start with a PDF header, then what appear to be blocks of random bytes (which are, in fact, the collision blocks) and only then some valid HTML – mostly JavaScript. But browsers are notoriously tolerant when it comes to invalid input and tend to happily ignore the parts they don't know how to parse. The JavaScript then references the 'HTML' file itself to check one of the bytes in the collision blocks and, depending on its value, sets the background colour to blue or red and displays one of two possible images:
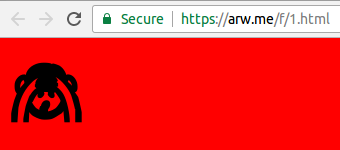
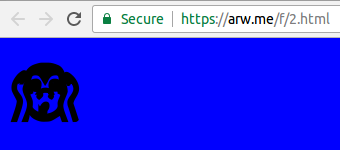
Now, imagine that rather than changing the image and the background colour the JavaScript, based on the value of one of the collision bytes, either executed an exploit or displayed a harmless animation. And imagine that web security products whitelisted 'good' HTML pages based on their SHA-1 value. The security product could be served the second variant of the collision, which it would determine to be harmless, and consequently whitelist the SHA-1. If it were subsequently served the first, harmful, variant, it would happily let it run.
No web security product looks at the SHA-1 of potentially malicious content, and they certainly don't whitelist content based on their hash. But SHA-1 probably is used for whitelisting executables. And it is not impossible for someone to be able to use the aforementioned trick to create two colliding executables of some kind where, for example, part of the collision block is the encryption key for another part of the executable. Depending on which variant is used, the encrypted content will either decrypt to something malicious or to harmless gibberish.
The difficulty here isn't so much constructing the executables but in finding an environment that is sufficiently tolerant of seriously broken executables (similar to the way in which browsers are very tolerant of broken HTML files). Research on 'polyglots' by Ange Albertini, one of the Google researchers that worked on the SHA-1 collision, has led me to believe that such an environment may exist.
A variant of this idea was used in the 'BitErrant' attack on BitTorrent, published earlier this week. BitTorrent works by splitting a file that is to be shared into blocks, the SHA-1 of each of which is used to prevent rogue peers from sharing an incorrect or malicious part of the file. The researchers behind 'BitErrant' created two portable executable (PE) files which would split into blocks with the same pairwise SHA-1 hashes, even though there was one pair of blocks that wasn't the same in the two files.
This pair contained the same collision as was found in the 'Shattered' attack and was, indeed, used to decrypt the actual malicious content of the PE files, so that one of the two files was malicious and the other wasn't. It should be noted here that this is an attack against BitTorrent (and a pretty theoretical one at that), rather than an attack on whitelisting based on file hashes: the PEs themselves didn't have the same SHA-1 hash.

A lot of the talk around the SHA-1 collision has been focusing on SHA-1 signed certificates. It is unlikely that these will become an issue, partly because we started the process of phasing them out long ago, and partly because an attack on such certificates would be orders of magnitude more difficult than finding two colliding PDFs.
SHA-1 remains widely used in other places too though. For each of these use cases, it is pretty unlikely that someone will be able to break them in the foreseeable future. But is is also extremely difficult to be certain that your particular use case isn't the exception.
So stop using SHA-1 now. There have long been better alternatives.